We are thrilled to announce the release of a brand new app: Gitora For Data.
Gitora For Data seamlessly integrates data in your tables with Git, enabling robust version control. Utilize any Git command for collaboration and effortlessly import any dataset version back into your chosen database. Gitora For Data is ideal for versioning metadata, business logic, Large Objects (LOBs), and value lists in your tables.
A Solution for Database Centric Applications
Many teams in the Oracle database community build database centric applications where most of the business logic, code, settings, workflows and even user interfaces are stored in the database tables. This has great benefits but it comes at a great cost: Lack of version control. Deprived of version control, database teams struggle to collaborate. Having two people working on the same application becomes a daunting task, a trivial undertaking for middle tier and web developers. Deploying changes from the development database to production fairs no better. A missing row in a table, a forgotten CLOB update causes havoc. Gitora For Data is our first attempt to provide a solution to these shortcomings.
Database centric application development is an area with a lot idiosyncratic implementations and no real industry wide standards. Accommodating the wide range of requirements may take additional features. We are looking forward to hearing from you. We fully anticipate that there will be unique needs and Gitora For Data application architecture is flexible enough to support a wide variety of requirements.
The HTTP request body must be a JSON object. The JSON object contains the name and the input parameter values of the API function being called. Below is the list of functions with an example to show how to call them:
Export:
JSON Object Specification:
method: export
input: A JSON Object that contains the input parameters to the export function.
input JSON Object properties:
database: Name of the database you want to export from.
repo: Name of the Git repo you want to export to.
message: Your Git commit message.
threads: Number of threads to use to export the data. (Defaults to 1).
The response from the server returns a JSON Object in the body. If the export function is successful, the object looks like the following:
{"status":"success"}
If the export function is not successful, the object looks like the following:
{"status":"error","error":"Some error message"}
Import
JSON Object Specification
method: import
input: A JSON Object that contains the input parameters to the import function.
input JSON Object properties:
database: Name of the database you want to import into.
repo: Name of the Git repo you want to import.
execute: Boolean. Set to true if you want to actually perform the import to the database. Set to false if you want to download the generated insert statements. Defaults to false.
The response from the server returns a JSON Object in the body. If the import function is successful and the execute property was set to true, the object looks like the following:
{"status":"success", "entityReports":[If there are any errors during the import they appear here other wise this property does not exist], "result":"Message that indicates that the import completed without errors. This property exists only if there are no errors during the import." }
Important Note: The status of the response can be success and the import can be a failure. The status property only indicates that the Gitora For Data server accepted and executed your request. It does not indicate that the import itself was successful. For import to be successful, there must be no entityReports property in the response. In other words, the result property must be in the reponse.
If the execute property was set to false, then the response contains a fileName property which you should use with the download function to download the generated script.
{"status":"success","fileName":"Use this value with the download function"}
If the import function is not successful, the object looks like the following:
{"status":"error","error":"Some error message"}
Clone
JSON Object Specification
method: clone
input: A JSON Object that contains the input parameters to the clone function.
input JSON Object properties:
source: A JSON Object that specifies the source repo that will be cloned.
source JSON Object properties:
database: Name of the database you want to clone from.
repo: Name of the Git repo you want to clone.
target: A JSON Object that specifies the target repo.
database: Name of the database you want to create the new repo in.
repo: Name of the Git repo you want to create.
databaseUser: Name of the database user to be associated with the new repo.
The response from the server returns a JSON Object in the body. If the clone function is successful the object looks like the following:
{"status":"success"}
If the clone function is not successful, the object looks like the following:
{"status":"error","error":"Some error message"}
Get
Returns the content of a file stored in the Git repo.
JSON Object Specification:
method: get
input: A JSON Object that contains the input parameters to the get function.
database: Name of the database you want to get from.
repo: Name of the Git repo you want to get from.
path: Path of the file you want to get. Start the path after the data folder. For example, if the repo is at directory C:\gitora\datastore\GitoraForData\repos\databases\DVD Rental\dvdrental_repo and the file you want to get is actor.json which is at the path C:\gitora\datastore\GitoraForData\repos\databases\DVD Rental\dvdrental_repo\data\actor\actor.jsonpath parameter value must be actor/actor.json . You can download an entire folder by specifying the path to the folder.
commitId: ID of the git commit you want to query from. If you want the current state of the file in the working directory, leave this property null or empty.
returnDownloadLink: If set to true, the function returns a download link that you can use to download the file. If set to false, the body of the response contains the file. Defaults to false. If a file is not a text file, the property is omitted. Binary files and folders are always returned as a downloadable link.
The response from the server returns a JSON Object in the body. If the get function is successful and the returnDownloadLink property is set to false the object looks like the following:
{"status":"success", "result":{"fileContent","This is the content of my file."}
If the returnDownloadLink property is set to true or the referenced path is a binary file or a folder then the request looks like the following:
{"status":"success", "result":{"filePath","use this path with the download function"}
If the get function is not successful, the object looks like the following:
{"status":"error","error":"Some error message"}
Download
Downloads a file
JSON Object Specification:
method: download
input: A JSON Object that contains the input parameters to the get function.
fileName: A file name that you received from other Gitora For Data API functions. You cannot pass any file name to this function and expect it to return it. The file must be created by another API function.
In this tutorial, we will add every table in the Oracle sample schema CO to the CO_REPO, extract the data in the tables, make some modifications to them, issue a git commit and import the data into another database.
Clicking the open button next to the repo in the Home Screen opens the Repo App in a new browser tab.
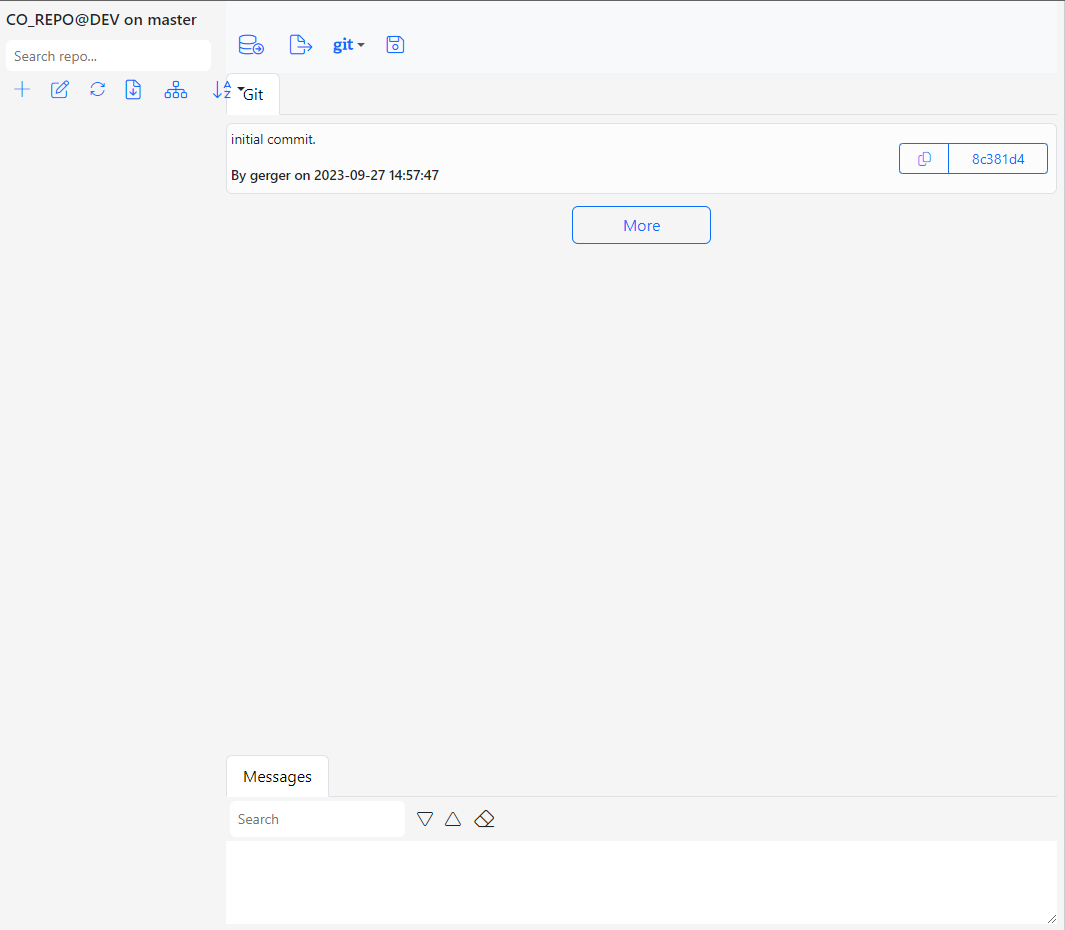
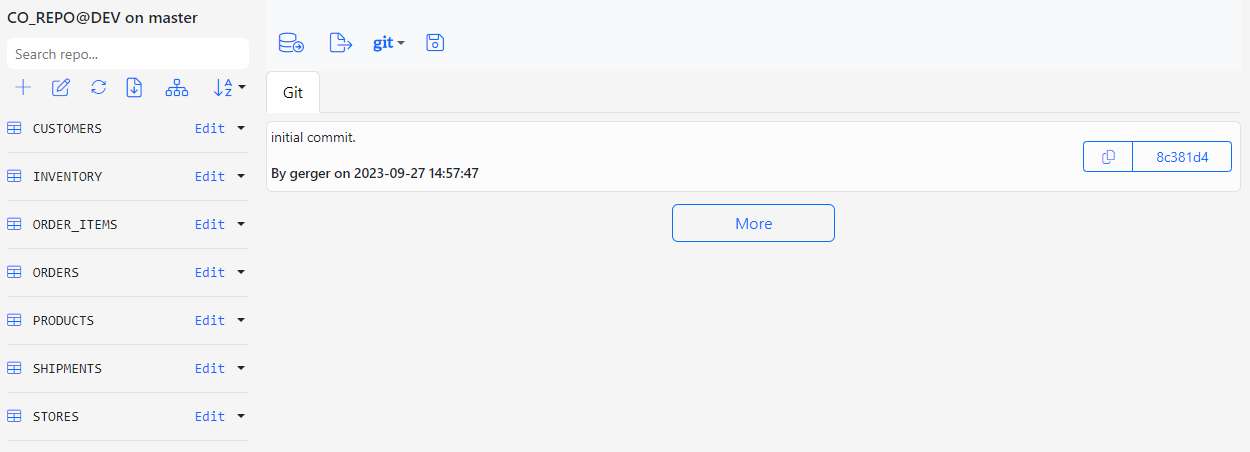
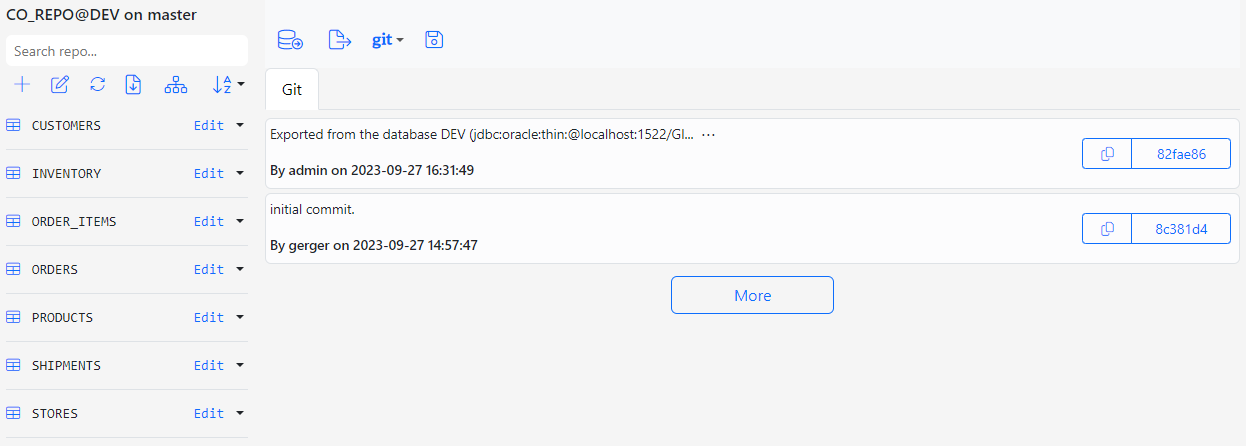
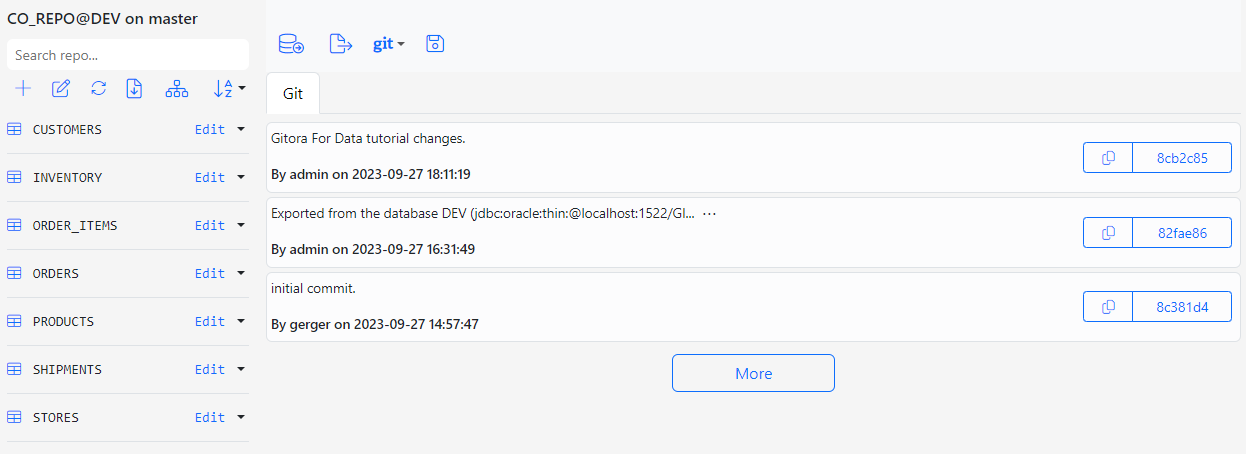
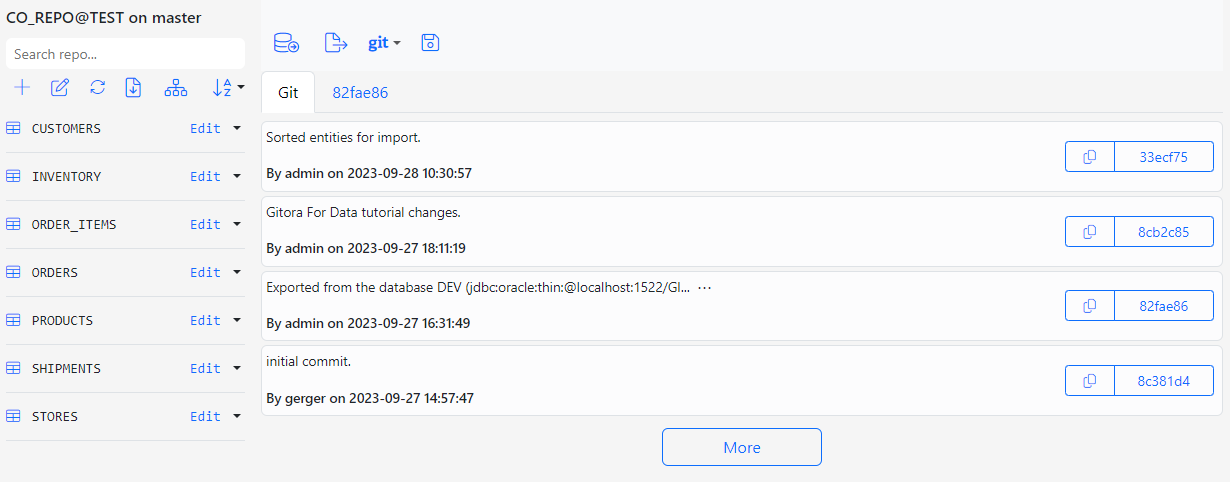
Below is the screenshot of the CO_REPO in its initial state.
At its initial state, the repo CO_REPO is empty and there is only the initial commit that stored the initial Gitora configuration file.
Following tutorials will focus on other git features such as branching, merging etc…
Creating Entities
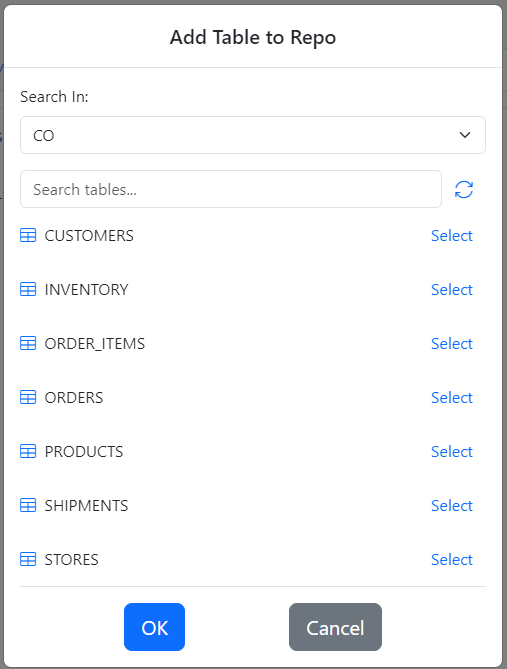
To add tables to the repo, click the plus sign on the left of the screen titled under the repo search field.
The Add Table to repo dialog shows up.
Select every table by clicking the Select button next to each table. Finally, click OK. Gitora will create an “Entity” for each database table. In Gitora parlance, an Entity is an SQL query with a target table. Gitora for Data can export and import entities.
Our repo looks much better now with seven entities.
We’ll talk about entities and what you can do with them in another tutorial. For the purposes of this tutorial, we are ready to export the data out of the CO schema in the DEV database.
Exporting Data to the Git Repo
Click the Export button which is the first button from the left, at the top of the screen.
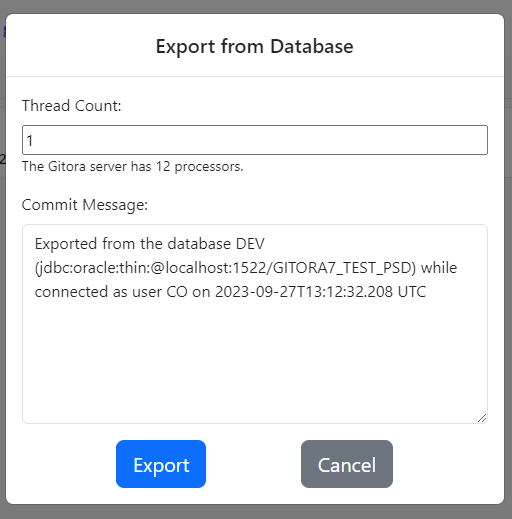
The Export dialog shows up.
Gitora can export the data in multiple threads in parallel. Gitora displays the number of processors in your server. We recommend picking a number below the processor count as the number of threads to be used for export.
Finally, Gitora adds and commits the generated files to Git. The more files there are the longer this process takes, although JGit is surprisingly fast at adding and committing files.
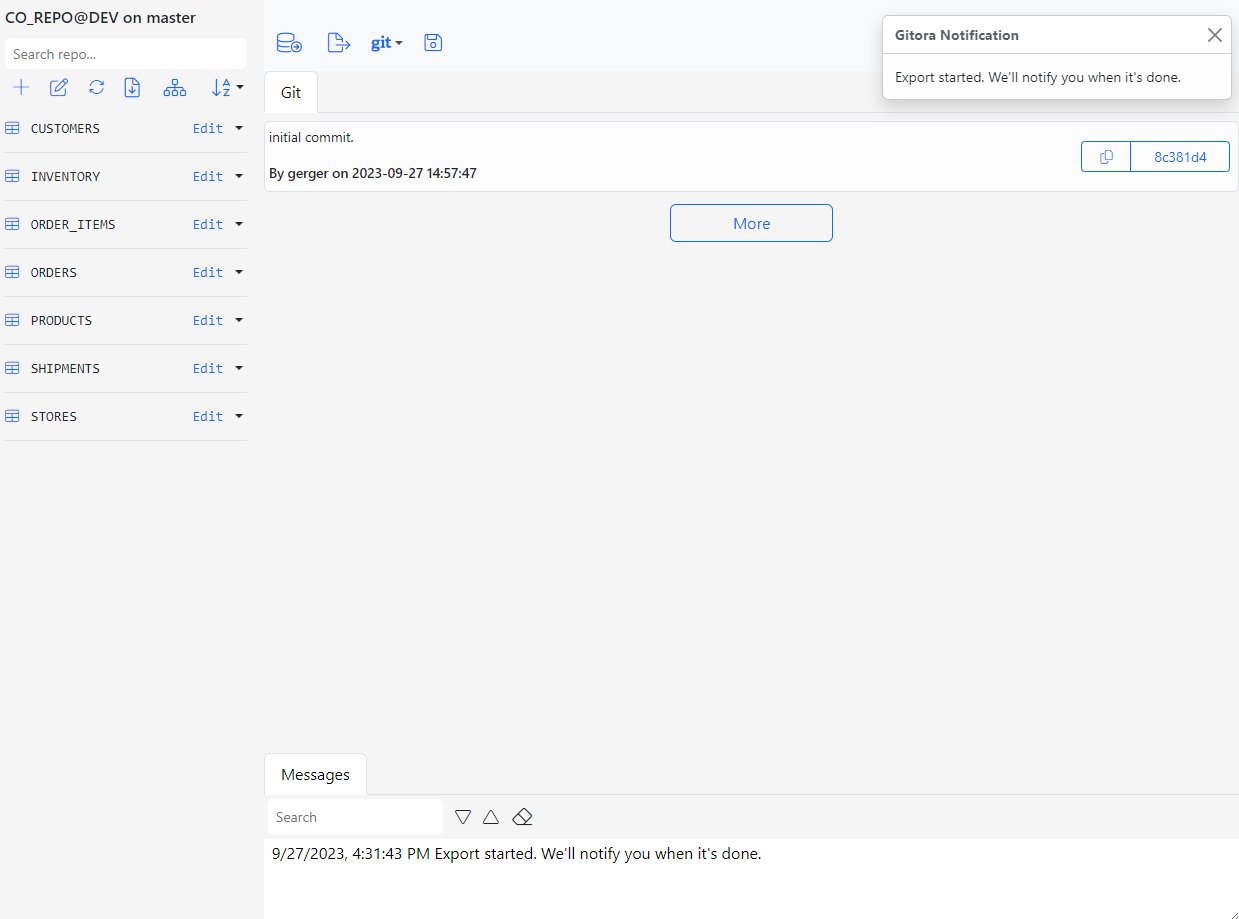
Enter a Commit Message and click the Export button. A notification will slide in from the right side of the screen, informing you that the export has begun and Gitora will inform you once it is completed. The same message is also displayed in the Messages tab at the bottom of the screen.
After a short while you will receive a second notification that informing you that the export is completed. The Message tab will also display the same message. The Git tab in the middle of the screen will show the new commit created by the export.
A Word On Export Speed
Gitora is not tested with large datasets and the goal of the product is not to support millions of rows. The CO schema has 8783 rows and Gitora exports the data quickly. Please note that the number of files generated by Gitora can change significantly depending on the File Generation Strategy you choose and the number of LOB columns the tables have.
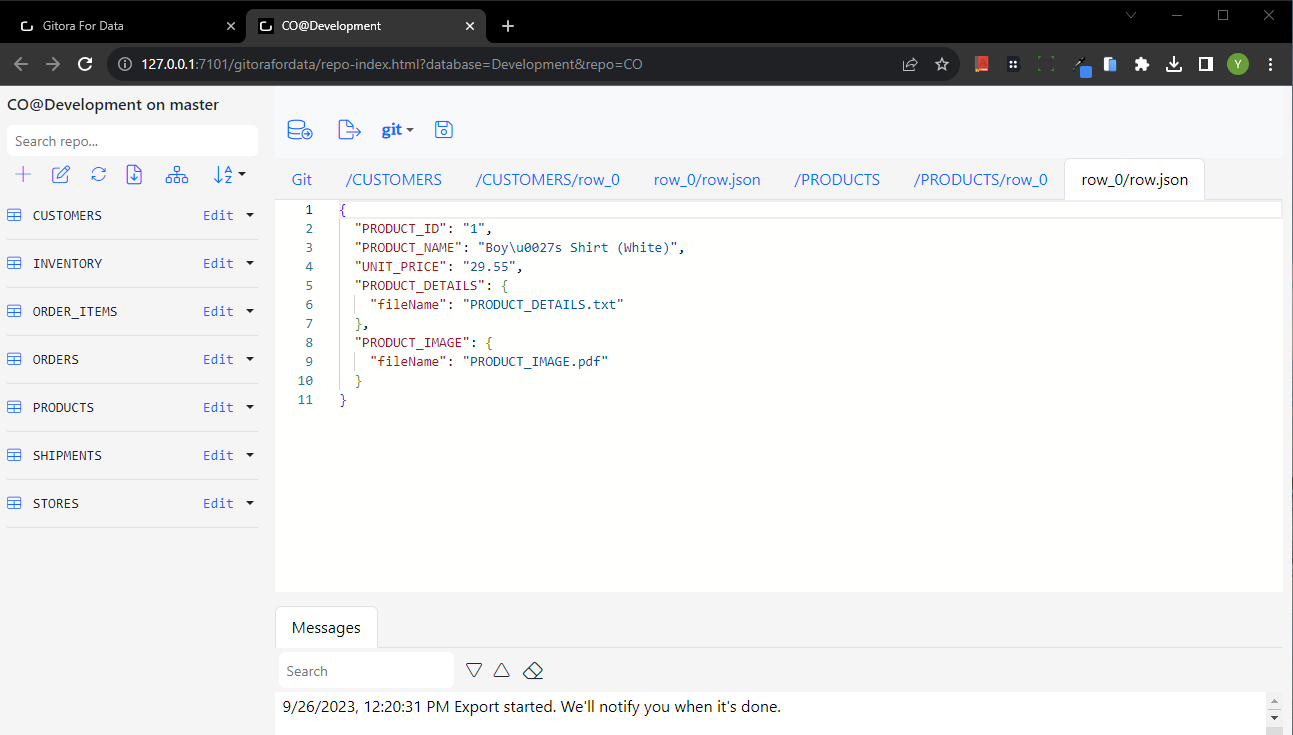
Browsing the Exported Data
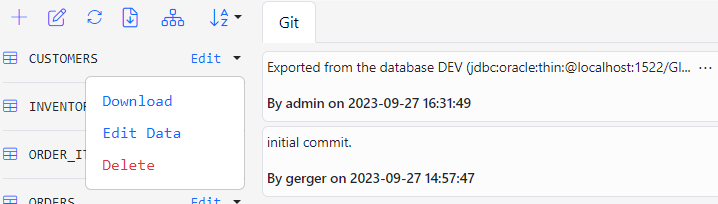
Click on the entity names or open the button group for each entity and select Edit Data to browse the generated JSON files.
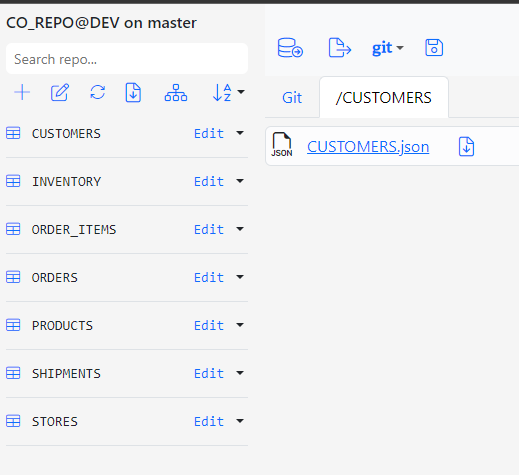
In the screenshot below, we clicked the CUSTOMERS entity to view the contents of the CUSTOMERS folder in the repo’s working directory.
Editing the JSON Documents
To edit the document, click the CUSTOMERS.json link. Click the download icon next to it to download the JSON file.
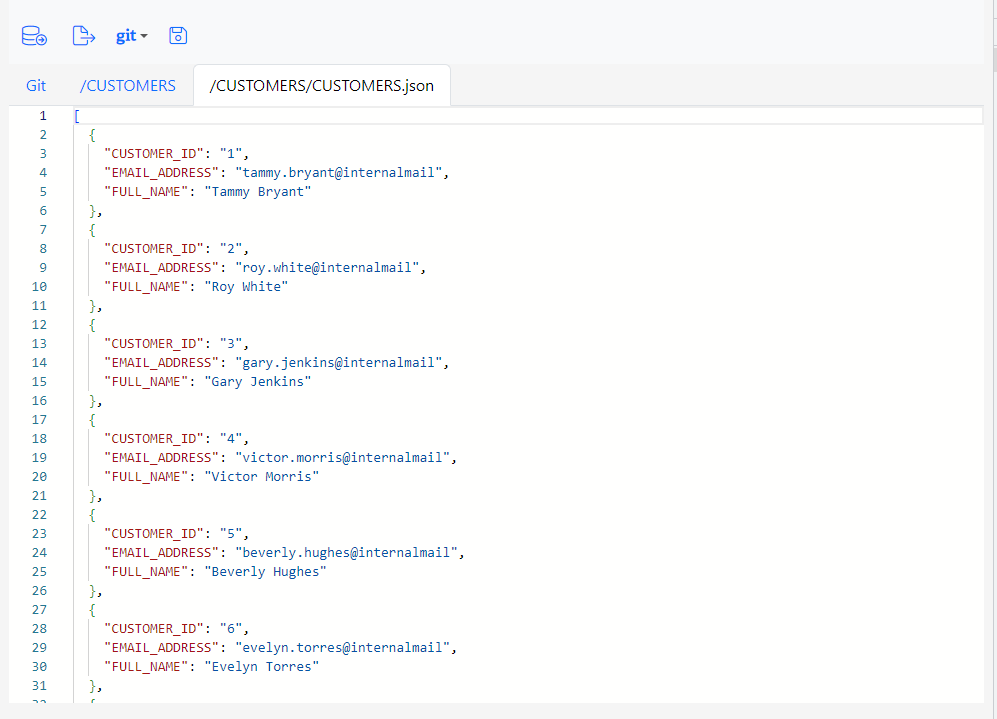
Gitora displays the data in a JSON editor that formats the document properly. Gitora also enforces the JSON syntax for the document. Trying to save the document with a JSON syntax error will cause an error.
For the purposes of this tutorial, change the name of the first customer to John Doe.
Click the Save button at the top menu to save your changes.
Viewing the LOB files
Click the PRODUCTS entity to view the data Gitora exported for products.
The PRODUCTS table contains a CLOB and a BLOB column named PRODUCT_DETAILS and PRODUCT_IMAGE respectively. The PRODUCTS folder contains the files generated for these LOB columns.
As with the JSON documents, you can view the LOB files in the browser (if it is a file type that can be viewed in a browser) or download them.
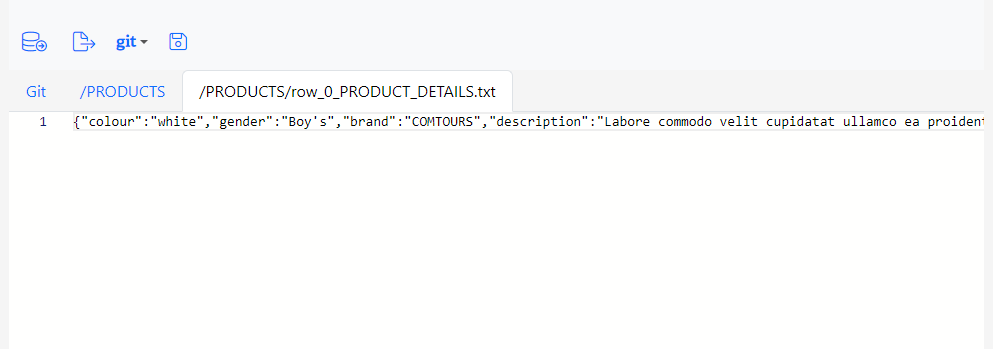
To view a CLOB file click on the row_o_PRODUCT_DETAILS.txt link. Gitora opens a plain text editor.
The text data stored in the PRODUCT_DETAILS column happens to be a JSON file (which is confusing for the purposes of this tutorial) but let’s ignore that for a moment. Stored in a CLOB, it could be any kind text data that we are viewing. Since the data is plain text, you can edit it within the Gitora for Data application and save your changes just like you would with a JSON file. Make a change to the file and click save.
To view a BLOB file, either click on the link for the file to view it in the browser or click the download button next to the link to download it.
Unfortunately, the original PRODUCTS table in the Oracle sample schema CO does not contain any BLOB data but we’ve added one for this tutorial.
Clicking the link row_0_PRODUCT_IMAGE.pdf will open the PDF file stored in this file in the browser.
Note that, Gitora can figure out common file types of BLOB data such as PDF’s, PNG’s JPEG’s etc… , automatically.
Committing the Changes
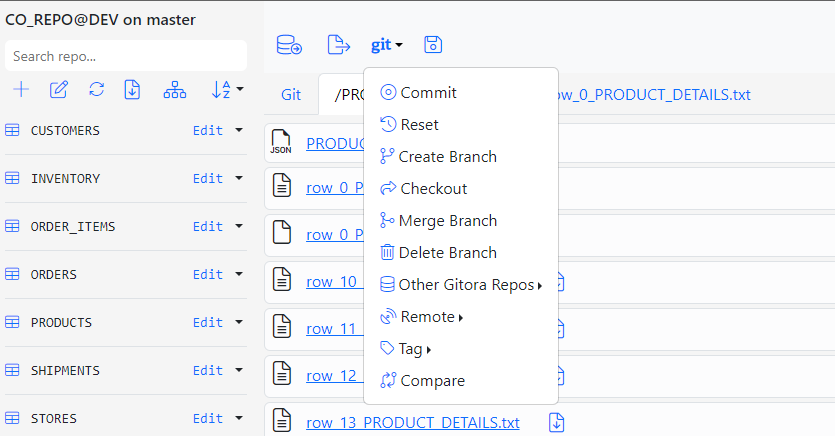
Committing the changes we made to Git is a straightforward git commit. Click the menu item named git at the top of the application and select Commit.
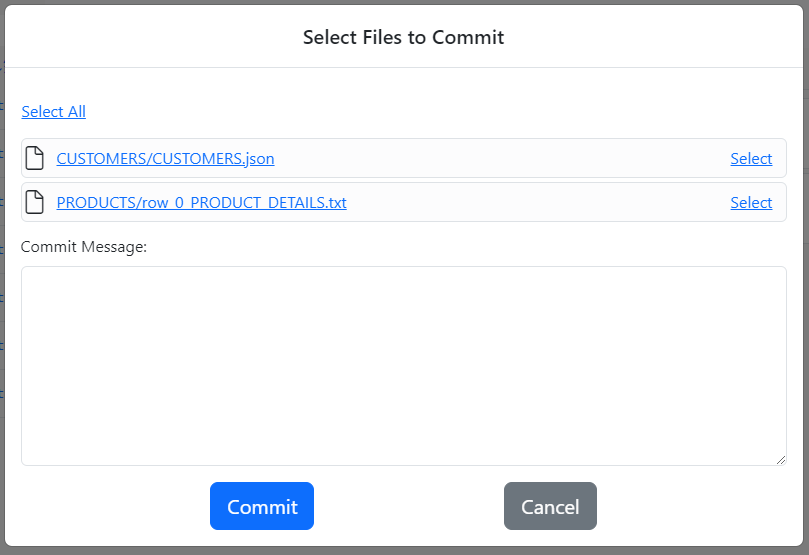
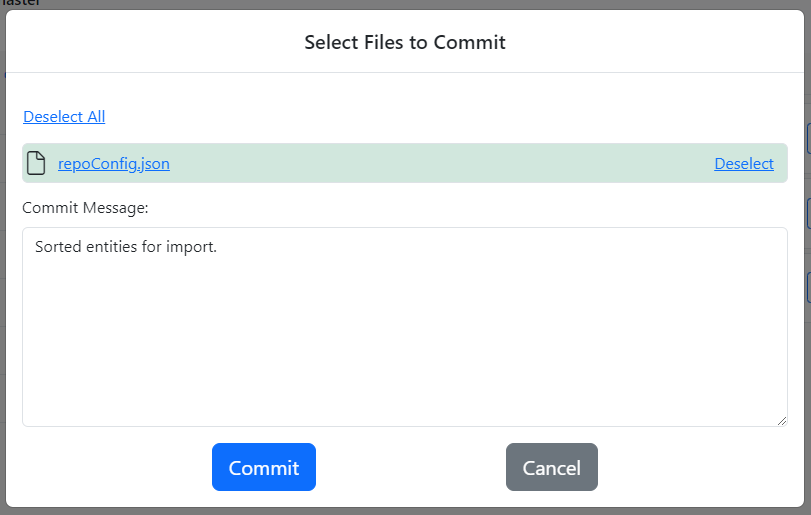
The Commit dialog shows up.
The Commit dialog lists the changed files that can be committed to the repo. Click the name of the file to open the diff editor in a new browser tab that highlights the changes made to the file since the last commit.
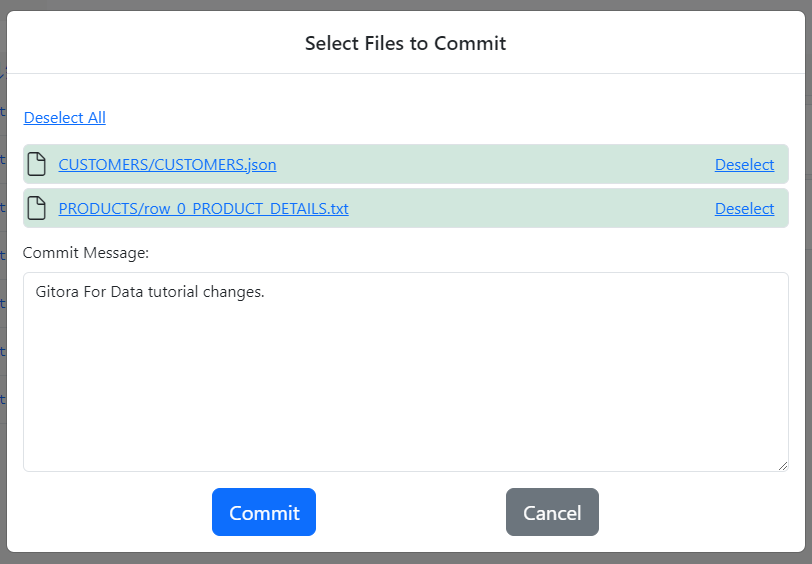
Select the files by either clicking Select All or by clicking the Select link for each file. Enter a short explanation to the Commit Message field and click the Commit button.
Clicking the Commit button closes the dialog and refreshes the Git tab to display your latest commit.
Ordering Entities for Import
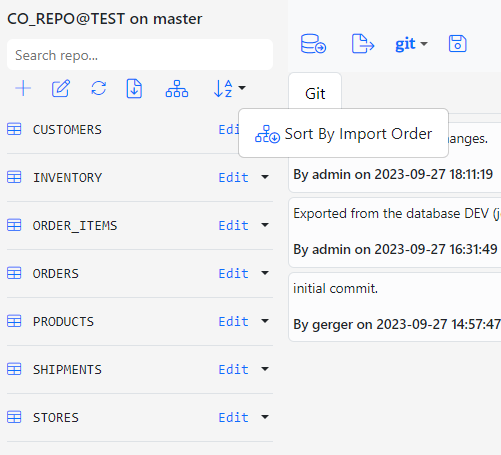
Gitora For Data allows you to set an import order for entities. Click the icon that looks like a hierarchy in the repo menu bar, the second icon from the right among the icons.
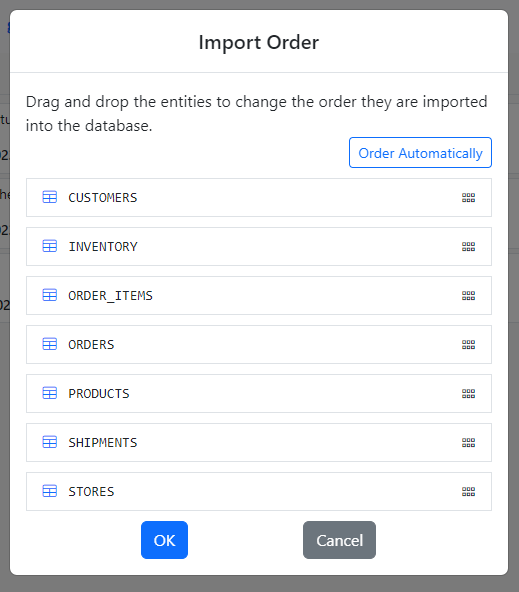
The Import Order Dialog shows up.
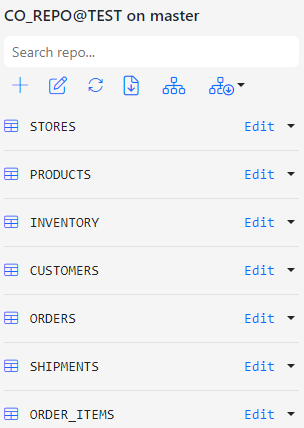
The CO schema has the necessary foreign key constraints to automatically infer the import order. Click the Order Automatically button for Gitora to order the entities.
Not all tables have the foreign key constraints to automatically infer the import order though. In such cases, drag and drop the entity names in the dialog to their correct order in the import. Gitora will start the import from the top of the list.
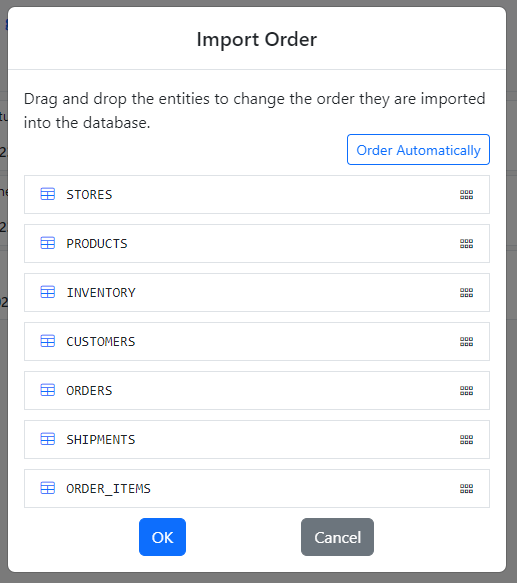
Below is the order of entities after Gitora sorted them automatically. Click OK to accept and save the order.
On the main screen, click the first icon on the right in the repo toolbar. Click the Sort By Import Order button to view the entities according to the order they will be imported to the database.
Finally, commit the changes to the import order to the repo.
A Note About the repoConfig.json File
repoConfig.json file is the JSON document that stores the Gitora specific information about your repo. It is part of your repo just like any other file. You should commit it to your repo just like any other file.
Moving Changes to Another Database
In the tutorial Getting Started with Gitora For Data , we clones the repo CO_REPO from the DEV database to the TEST database. The repo was empty then. Now we have data in the repo and even some changes.
Go back to the Home screen and open the CO_REPO in the TEST database. A new browser tabs opens displaying the CO_REPO@TEST repo.
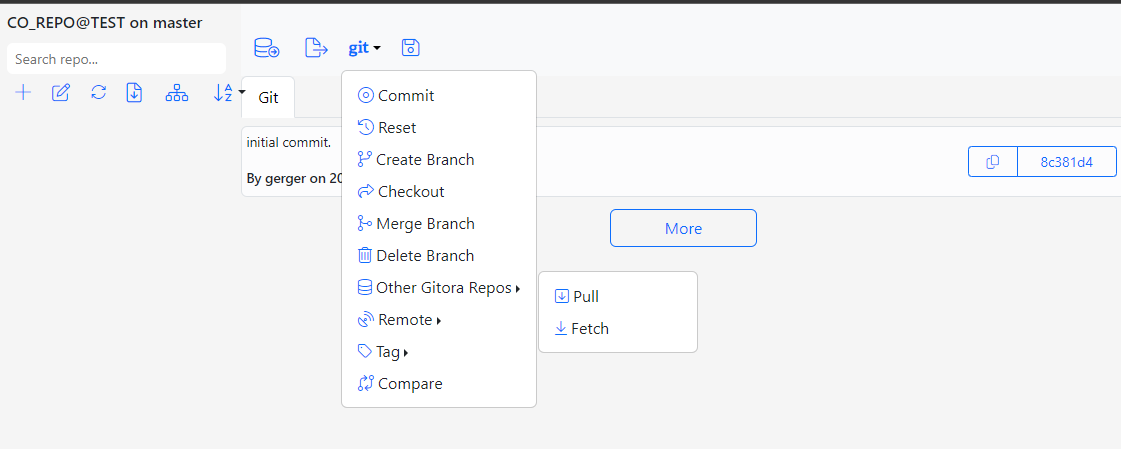
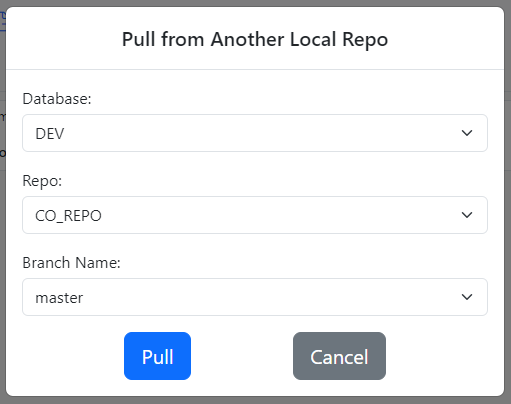
From the top menu select git – > Other Gitora Repos – > Pull
The Pull Dialog shows up. Select the DEV database, the CO_REPO and the master branch from the select boxes respectively.
Click the Pull button to move the changes from the CO_REPO@DEV to the CO_REPO@TEST.
The dialog closes and the Repo app is refreshed with the newly pulled commits and entities.
Importing the Data
Gitora For Data generates insert statements based on the data data in the working directory of the git repo. In other words, you should set the state of the files to the commit id you want to import into the database. In this tutorial, we will import the latest version of the data which is already active in the working directory.
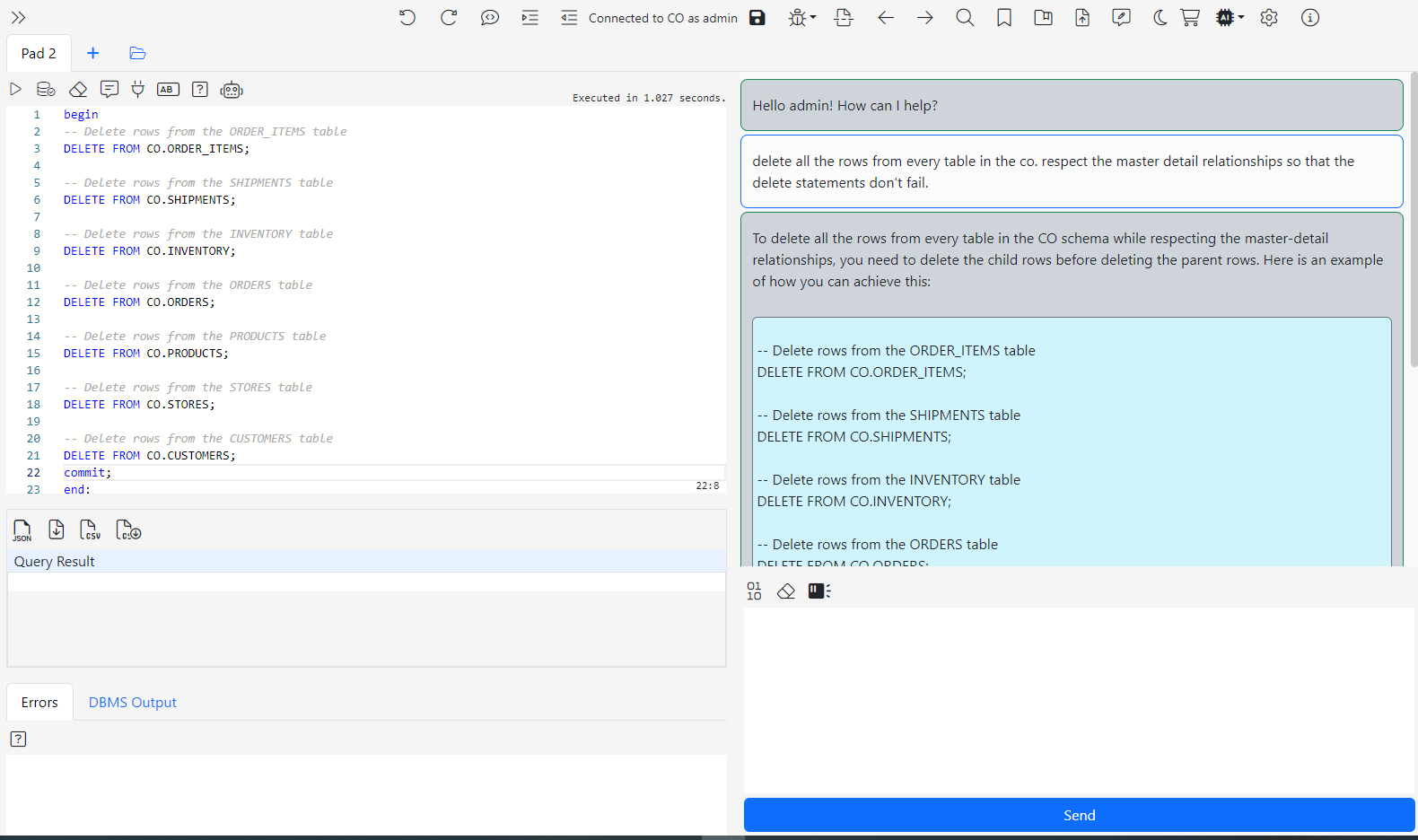
Connect to the CO@TEST database using Gitora PL/SQL Editor. Delete any unwanted rows from the CO schema tables. Since our repo contains all the data we need, we deleted all the rows from the schema by shamelessly plugging our Gitora Editor’s AI Chat feature to this tutorial:
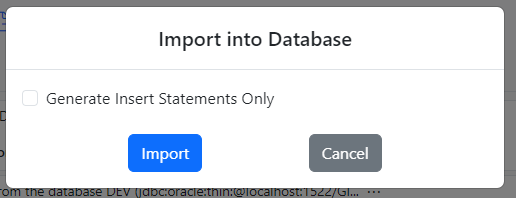
Next, go back to the Gitora For Data app and click the Import button, the second icon from the left.
The Import Dialog shows up.
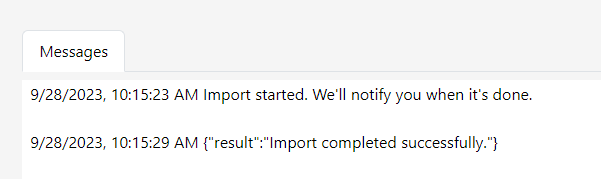
Click the Import button. Gitora will populate the CO schema with the data in the repo and inform you with a notification and a message in the Messages section at the bottom.
In this tutorial we showed how you can use Gitora For Data to:
Export data from a database to a Git repo
Browse and edit the data in the repo and commit the changes.
Move the repo and import the data to another database.
The first time you start Gitora For Data (usually via http://yourdomain/gitorafordata/index.html) the login screen shows up. Enter the default username and password admin/admin and click the Sign In button.
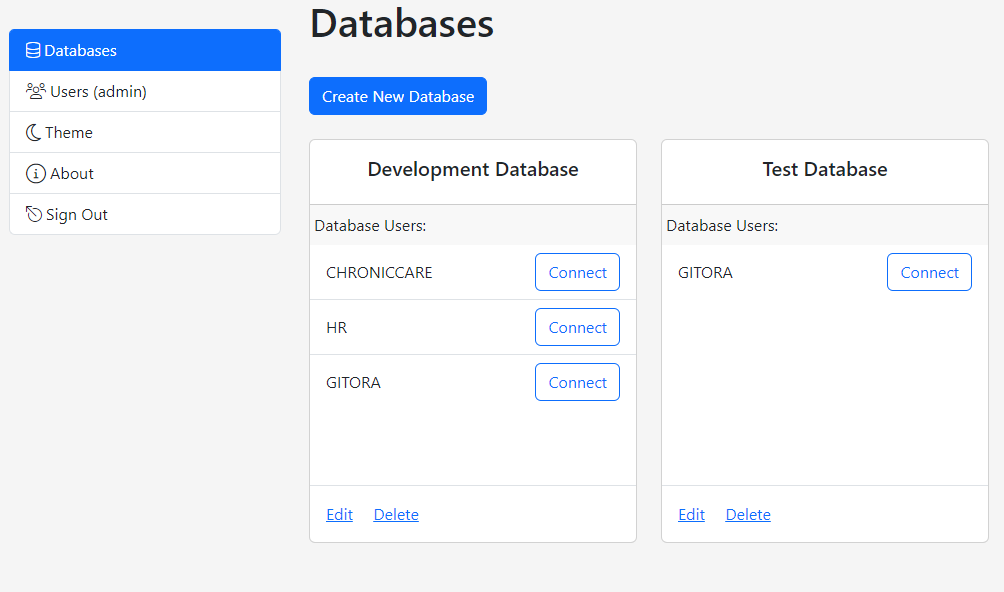
Since there are no databases registered to Gitora For Data yet, the Create New Database Connection Screen will show up.
Gitora will create database sessions using the credentials you enter on this screen so that it can query the tables and perform DML operations. Therefore it is important that the database user you enter has the necessary privileges to perform these tasks. You can add additional users to a database later but you need at least one.
Click the Save button to register your first database.
We will use the Oracle sample schema CO throughout this tutorial.
The Home Screen
Clicking the Save button takes you to the Home Screen.
The Home Screen is used for the following functions:
Search, register, edit and unregister databases from Gitora.
Create, clone, delete, search and open repos.
Create, edit and delete database users.
Search, create, edit and delete Gitora For Data application users.
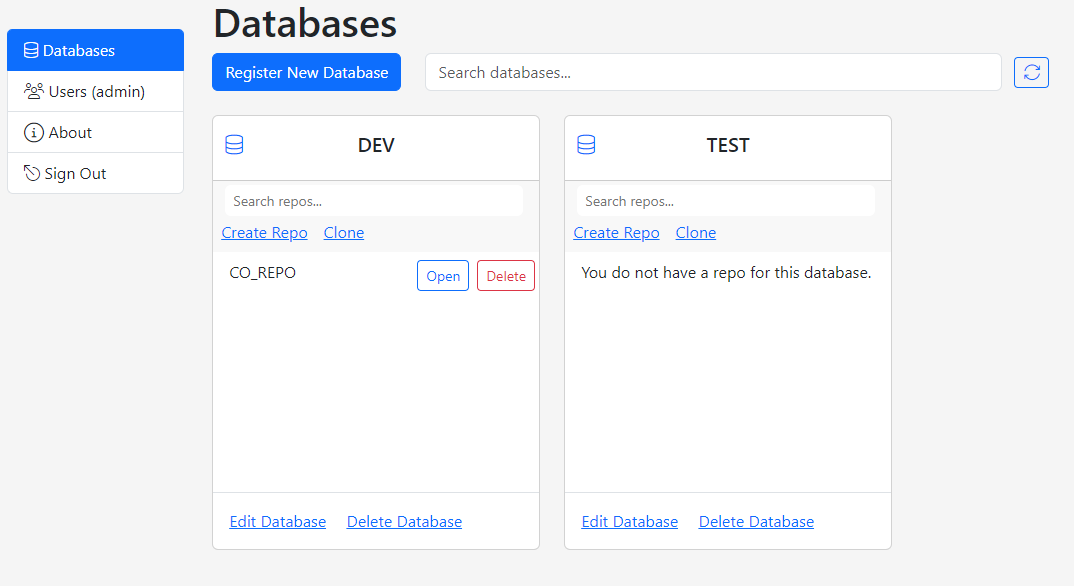
The Home Screen consists of two sections. The navigation column and the main area.
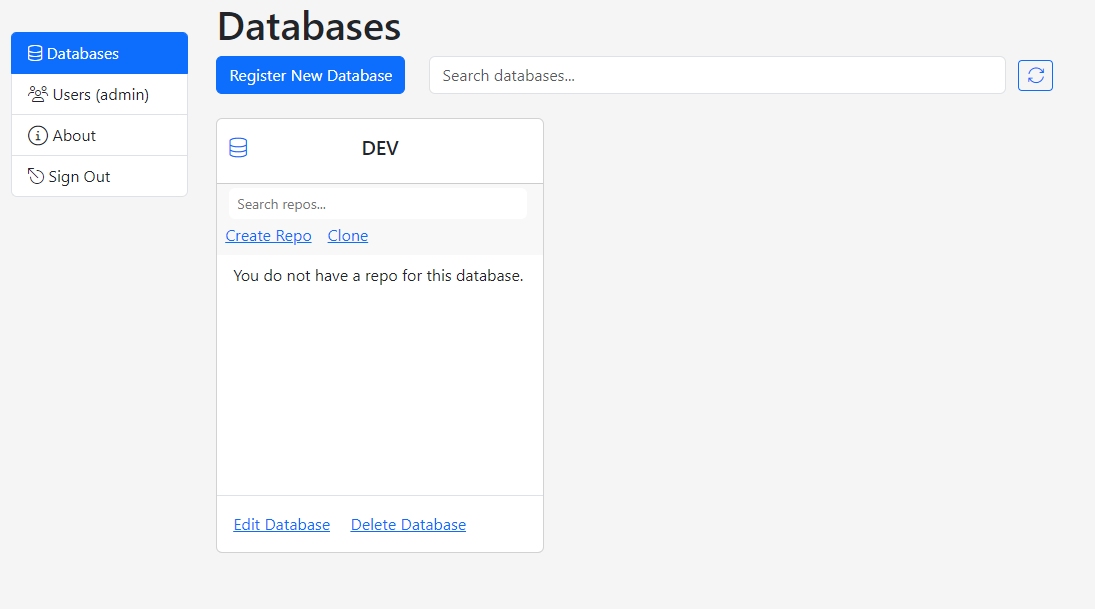
By default, the home screen starts with the Databases tab which lists all the databases that are registered to Gitora.
Creating Your First Repo
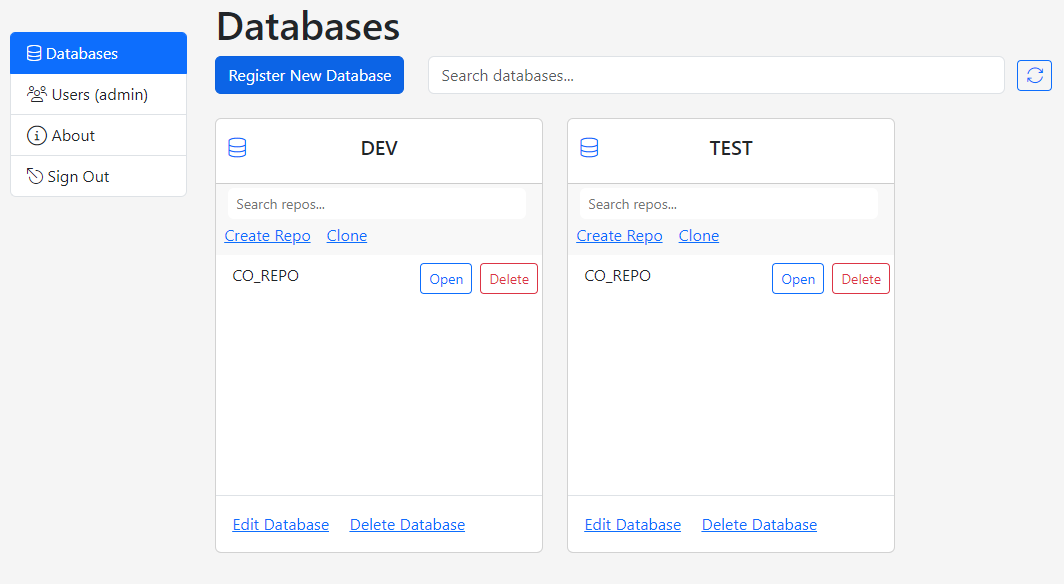
In Gitora For Data, each registered database is represented with a Database Card on the home screen. The database card can be used to edit and delete a database as well as to search, create, clone, delete and open Git repos associated with the database.
Our first database does not have a repo yet. So let’s create one.
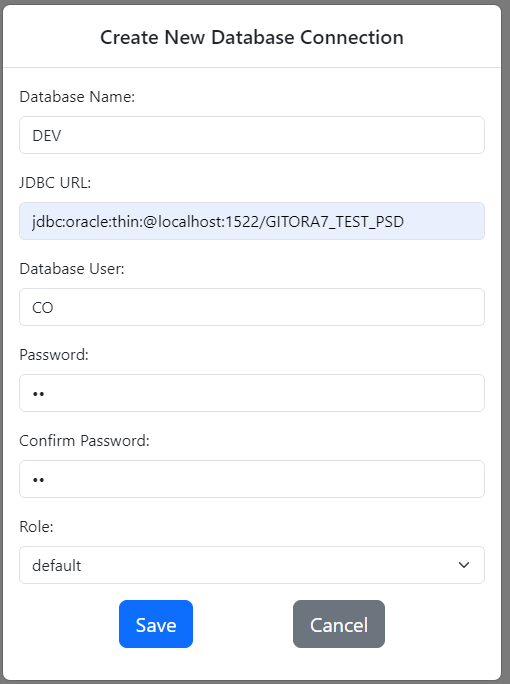
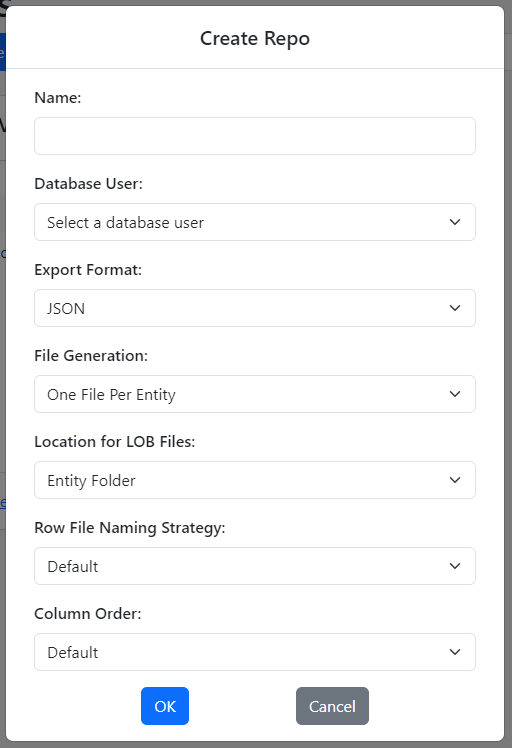
Click the Create Repo link in the DEV database card. The Create Repo dialog shows up.
The dialog displays several fields. Let’s go over them one by one:
Name: This is the name of your repo. It will be the name of the top folder of your Git repo where the .git folder resides.
Database User: Gitora needs to know which database user this repo will connect to so that it can query data from the DEV database.
Export Format: Select the notation the exported data is represented in. (Currently, JSON format is supported. More options will be added based on customer feedback.)
File Generation: Gitora can generate file or files for the rows in a table using the following output strategies:
a) One File Per Entity
Using this strategy, Gitora will create one JSON file that contains all the rows in the table. For example, if you want to export the data from the EMPLOYEES table, Gitora will create a file at EMPLOYEES/EMPLOYEES.json and store all the rows in the EMPLOYEES table in this file.
b) One File Per Row
Using this strategy, Gitora will create a new JSON file for each row in the table. For example, for the table EMPLOYEES it will create files like so: EMPLOYEES/row_0.json, EMPLOYEES/row_1.json, EMPLOYEES/row_2.json etc…
c) One Folder Per Row
Using this strategy, Gitora will create one folder for each row like so: EMPLOYEES/row_0/row.json, EMPLOYEES/row_1/row.json. This option is more suitable if your tables contain LOB columns. For example, if the EMPLOYEES table contained a column named PICTURE_BL, the output would look like the following: EMPLOYEES/row_0/row.json, EMPLOYEES/row_0/PICTURE_BL.png.
Location for LOB Files: Gitora can export LOB data to files. You can choose one of the following options to create the files for LOBs.
a) Entity Folder
Gitora will create the LOB files under the entity folder which is usually named after the table. For example, files for LOB data in the EMPLOYEES table will be created under the EMPLOYEES folder in the repository like so: EMPLOYEES/row_0_PICTURE_BL.png, EMPLOYEES/row_1_PICTURE_BL.png etc…
b) Subfolder under Entity Folder
Gitora will create the LOB files under the lobs directory of each entity. For example the file structure under the EMPLOYEES folder will look like the following: EMPLOYEES/lobs/row_0_PICTURE_BL.png, EMPLOYEES/lobs/row_1_PICTURE_BL.png
c) One Folder Per Row
Gitora will create a folder for each row and place the LOB files of the row under it like so:
Note that, this option can be used in conjunction with the File Generation strategy One File Per Entity. In this case, all rows of the EMPLOYEES table will be in the EMPLOYEES/EMPLOYEES.json file and the files for LOBs will be in folders generated for each row: EMPLOYEES/row_0/PICTURE_BL.png, EMPLOYEES/row_1/PICTURE_BL.png etc…
Row File Naming Strategy: This option determines the strategy Gitora uses to name the files Gitora creates for each row. Gitora can create a file for each row and/or a file for each LOB column in the row. Gitora will use the selected strategy whenever it creates these files.
a) Default
The Default strategy assigns a number to each row starting from 0. The rows are numbered in the order they are received from the Entity’s SQL query. Therefore, it is important to order the data by a column (or columns) that do not change their value over time. By default, Gitora orders rows by their primary key column value(s). If the table does not have a primary key constraint, Gitora uses the first column in the Entity query like so: select * from table order by 1
b) From Primary Key
Gitora generates row file names using the primary key column value(s) of the table. Assuming the primary key of the COUNTRIES table is NAME_TX, the rows Gitora generates will be: COUNTRIES/row_USA.json, COUNTRIES/row_GERMANY.json etc…
Please note that, the primary key values must not contain any characters that cannot be used in file names.
Column Order: Specify the order in which the table columns appear in the JSON document.
a) Default
The columns are ordered as they appear in the SQL query of the Entity. For example, if the query for the COUNTRIES entity is “select region, name from countries” then the JSON document for the country USA will look as follows:
{“region”:”North America”, “name”:”USA”}
b) Alphabetically
As the name of the option suggests, the columns will be ordered alphabetically in the JSON document. For the same query as above, the JSON document will be as follows:
{“name”:”USA”, “region”:”North America”}
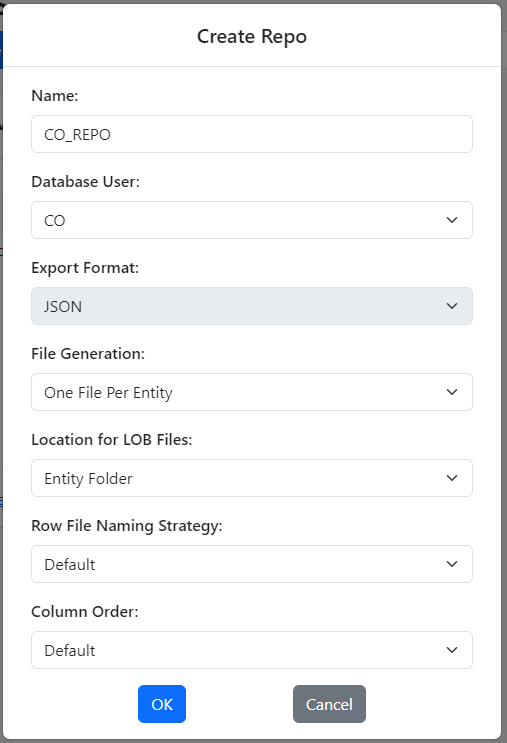
Below are the values for each field for our first repo:
Click OK to create your first repo.
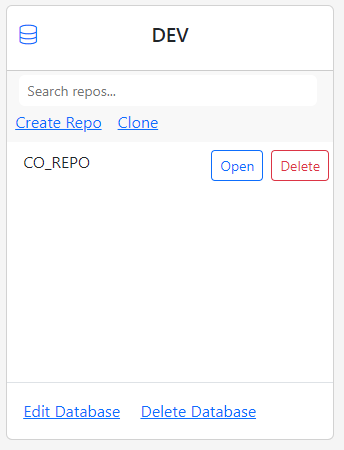
The database card for DEV database shows the first repo you created.
Working with a Repo
Clicking the Open button opens a new browser tab and takes you to the Repo App where the actual stuff happens. Therefore, the repo maintenance deserves its own tutorial. Click here to learn how you can edit a repo, export data to a repo, perform Git operations on the data and finally import your data back to a database.
Deleting a Repo
Click the red Delete button next to a repo to remove it and its contents. Select Yes to confirm and your repo will be deleted.
Cloning a Repo
The Clone button in the Database Card clones a repo and associates the clone with a database.
Although you can clone a repo and associate the clone to the same database, it makes more sense to clone a repo and associate it to a new database. This is how you can move your data from one database to another using Gitora For Data.
To achieve this, let’s create another database first.
Click the Register New Database button and repeat the steps you followed to register your first database. It goes without saying that you should use a different name and JDBC connection string for the new database.
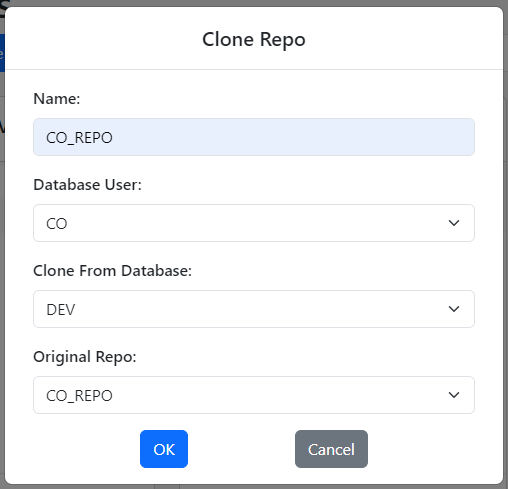
Click the Clone button under the TEST Database Card. The Clone Repo dialog shows up.
Fill out the fields as follows:
Name: Enter a name for your new repo. Since we are cloning the CO_REPO repo, it makes sense to name this repo CO_REPO as well.
Database User: Specify the database user Gitora should use to perform export/import functions for this repo. Since this repo manages data in the CO user, it makes sense to select the CO user.
Clone From Database: We want to clone the CO_REPO from the DEV database to the TEST database, so select the DEV database in this select box.
Original Repo: Select the repo you want to clone from the DEV database. In our case, this is the CO_REPO.
Click the OK button to clone the repo.
The TEST database card shows the cloned repo.
Unregistering a Database
Click the Delete Database button on a database card and select Yes to confirm to remove the database and all its associated repos from Gitora For Data.
Editing a Registered Database and Its Users
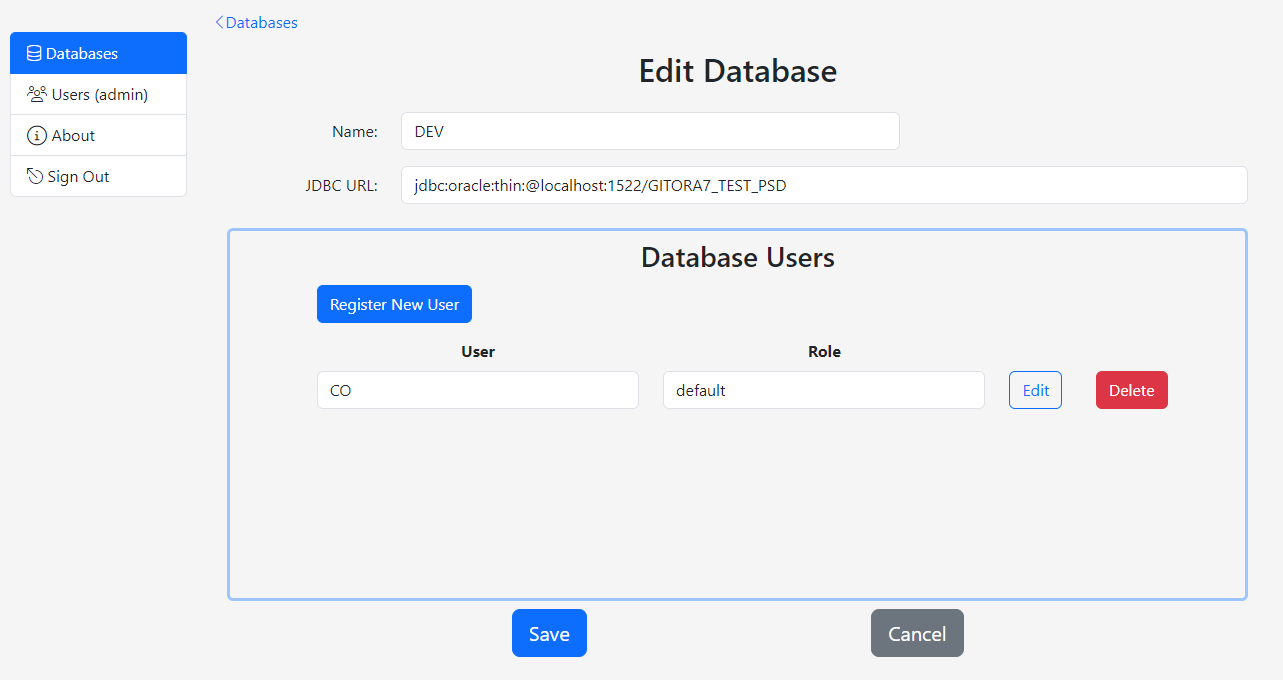
Click the Edit Database button on the database card. The Edit Database screen shows up.
Use this screen to edit the database name and the JDBC URL to connect to the database.
Use the Register New User button to add additional credentials to connect to the database. Use the Edit and Delete buttons to update and remove the existing credentials respectively.
Working With Gitora For Data Users
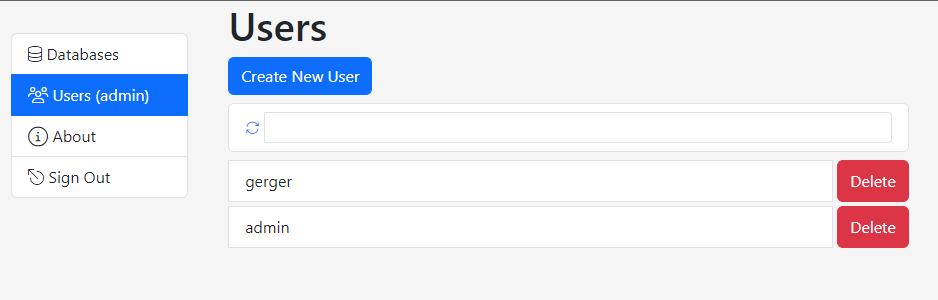
Click the Users tab to work with the application users.
Use the Create New User and Delete buttons to add or remove a user respectively. Click on a user to change its password.
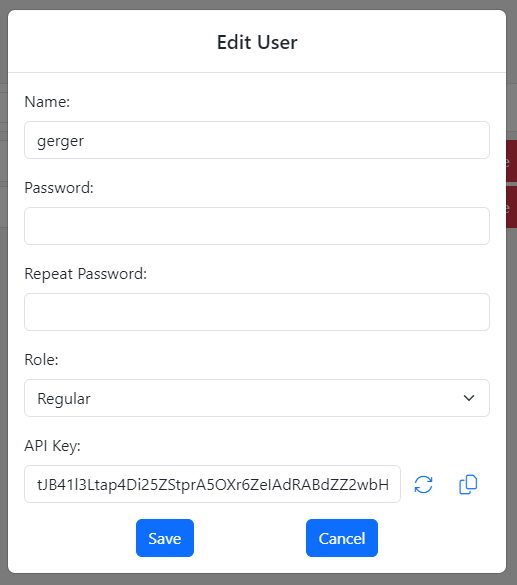
Generating and Using API Keys to work with the Gitora For Data API
The Edit User screen is also where you can generate and update a user’s API key. You need a valid API key to be able to work with the Gitora For Data API.
Click the refresh button to generate a new API key. Generating a new key, invalidates the existing key of the user. Click the copy button to copy the key to your clipboard.
Gitora 2.0 has a fully featured PL/SQL Debugger. Best to my knowledge, Gitora PL/SQL Debugger is the first and the only web application with a PL/SQL debugger.
Gitora Debugger also supports multiple debugging session at the same time.
First a foreword: AI is real and it is here. Its implications for knowledge workers will be enormous, including you the database developers.
There is no escaping AI in our line of work. Therefore, while building this version of Gitora, I’ve fully embraced it.
The last few months have been the most interesting, rewarding and productive period of my professional life. I’ve practically stopped using Google search and StackOverflow, two websites I’d consider essential to my work just a few months ago.
I’ve coded the Gitora PL/SQL debugger virtually without reading a single line of documentation about how to build debuggers in Java or the specifics of how to build a Java debugger for PL/SQL. I am not even sure if there is any documentation available about building a PL/SQL debugger on the Internet.
I just talked about these topics with ChatGPT and analyzed the code snippets it produced.
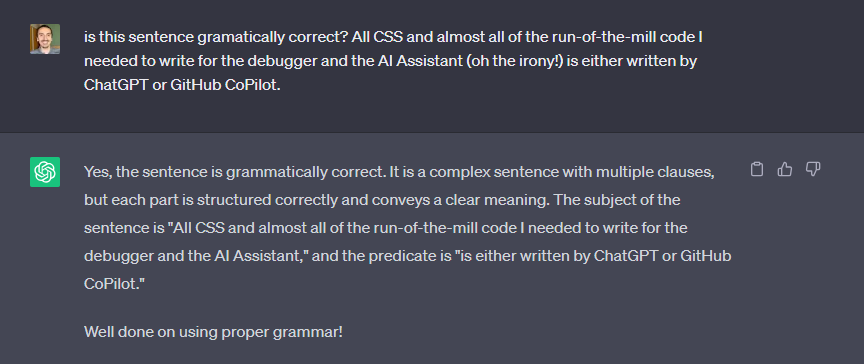
All CSS and almost all of the run-of-the-mill code I needed to write for the debugger and the AI Assistant (oh the irony!) is either written by ChatGPT or GitHub CoPilot. Heck, I even had the previous sentence grammatically verified by ChatGPT. I got it right in my first attempt and ChatGPT congratulated me.
I view AI as an amazing junior pair programmer who I am working with. My goal is to create the same feeling for you with the Gitora AI Assistant.
In Gitora Editor 2.0 the AI Assistant shows up in several places.
Chat with the AI Assistant
You can chat with the AI Assistant to write, debug, explain and improve your SQL and PL/SQL code.
This is a free form conversation with the AI Assistant very much like the experience with the ChatGPT. The difference is that Gitora automatically informs the AI about the context of your message. Behind the scenes, Gitora sends the information about the tables, their structure and their relationships to the AI Assistant, helping it to write SQL and PL/SQL relevant to your context.
You can send the code you are working on and the errors you receive during execution to the AI Assistant with just a click, along with the relevant context of course.
Links for the tutorials with complete details about how to configure and use the Gitora AI Assistant are below:
While you are coding, the Gitora AI Assistant uses the OpenAI GPT Turbo to suggest SQL and PL/SQL code and entire functions, procedures in real-time, right from the editor.
The Code Assistant is not aware of your database objects, their structures and relationships yet, so it is more of an experimental feature.
I’ll continue integrating AI to all aspects of database development to create your favorite junior pair programmer. If you think this is interesting, please download the Gitora PL/SQL Editor. You can support my work by providing feedback via email, Twitter or LinkedIn. Obviously, the best way to support my work is to purchase a subscription. 🙂
This article explains how to use the Gitora AI Chat feature.
The Gitora AI Assistant can help you write, debug, explain and improve SQL and PL/SQL code.
Gitora AI Chat uses OpenAI GPT. If you have not done so already, please follow the steps at this link to create an OpenAI account, register your API Key with the Gitora and open the PL/SQL Editor.
The AI Chat UI
If one is not already open, click the + sign in the editor and open an SQL Pad.
An SQL Pad will show up. Using the plug icon, assign a database connection to the SQL Pad, if it does not have one already.
Gitora uses this database connection to teach AI about the tables and their relationships in your database. Gitora NEVER queries the data in the tables and send them to the OpenAI servers.
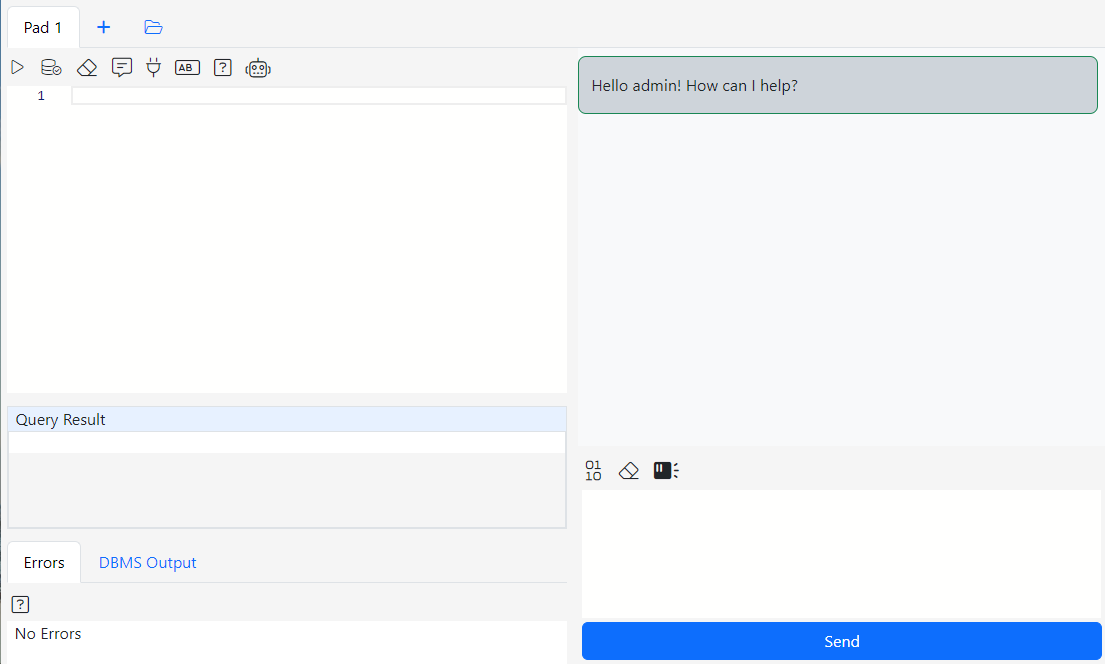
The SQL Pad has two button on the right that are of interest. We’ll start from the robot icon. Click the robot to open the AI Chat window.
The AI Chat window has two sections. The upper section displays your dialog with the AI. The lower section is where you type your messages to the AI.
The Ai Chat window has a three menu button. From left to right:
SQL Only: Toggling this button on will make the AI skip the explanations and reasoning and return only code.
Start Over: Clicking this button will erase all the context and the previous conversation with the AI.
Table Sensor: The AI examines your message and automatically infers what tables it needs to know about. This feature is on by default and I highly recommend to keep it that way. If you have more than 1500 tables in the schema SQL Pad is connected to and if you are not happy with response times of the AI, experiment with turning the Table Sensor off to improve response times.
Chatting with the Gitora AI Assitant
In this example, we are connected to the Oracle Sample Schema CO which contains the following tables:
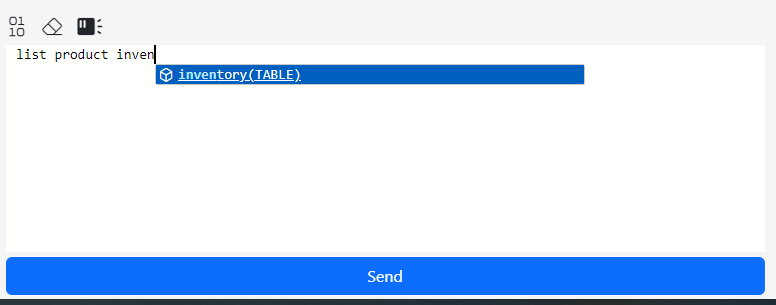
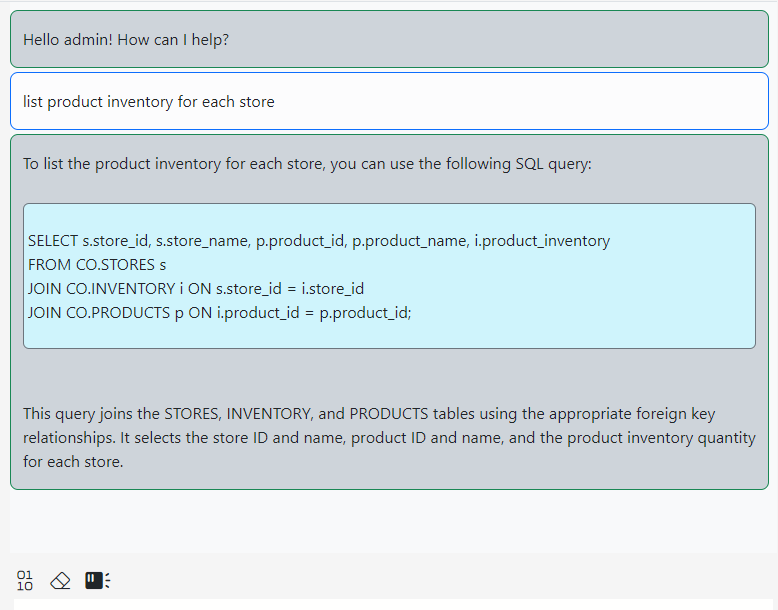
We ask the AI to write a query for us: List product inventory for each store.
Hint: As you type, the auto suggest feature in the editor recommends completions. Making a selection from the list will add the selected table to the AI’s context explicitly. If the Table Sensor is on, making a selection is unnecessary almost all the time. So do not feel compelled to make a selection or get the table name right. The AI will figure it out. However, if the Table Sensor is off, making an explicit selection from the completions dialog is the only way you can inform the AI about the context of the question.
Pressing the Enter key or clicking the Send button will submit your message. In a few seconds, the AI response will show up.
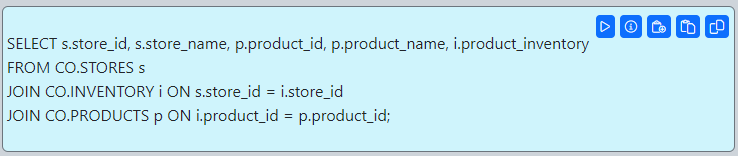
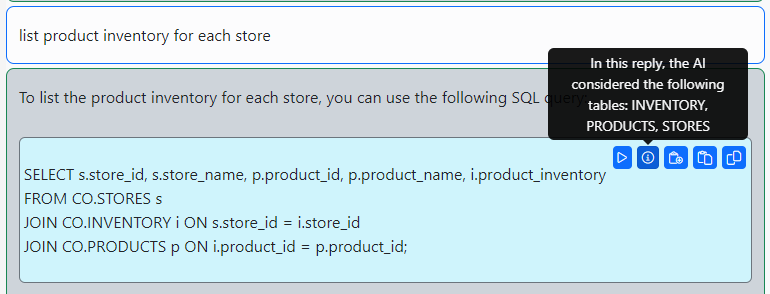
There are a few things you can do with this response. Hover your mouse over the highlighted SQL in the AI response. A menu will show up.
From left the right, the menu buttons are as follows:
Execute: Runs the Ai generated SQL and displays the results in the SQL Pad.
Info: Hovering over this menu item, lists the tables the AI considered while generating the query.
Hint: If the Table Sensor is on and you do not see a table that you expect the AI to include to the query, in the information popover, then add the table to your next message. For example write something like “Use ORDER_ITEMS table.”
Append to Pad: Appends the query to the SQL Pad.
Paste to Pad: Overwrites the text in the SQL Pad and pastes the query.
Copy: Copies the query to the clipboard.
The AI does not always produce correct SQL queries. If this is the case, you can inform the AI about the error to help it fix its mistake.
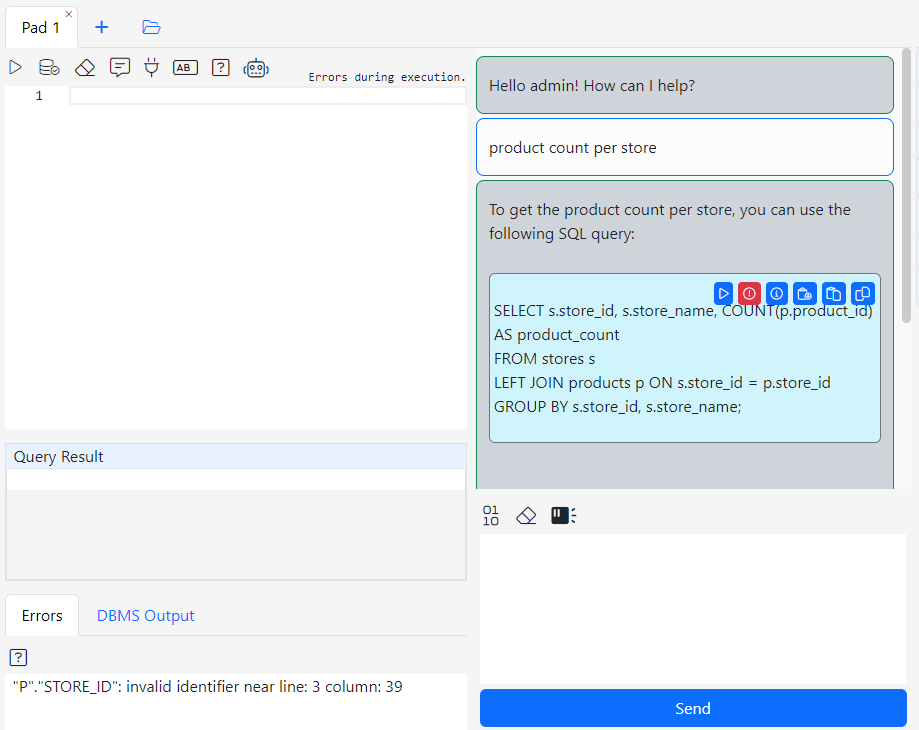
For example, if write the following message, the AI creates an invalid query:
product count per store
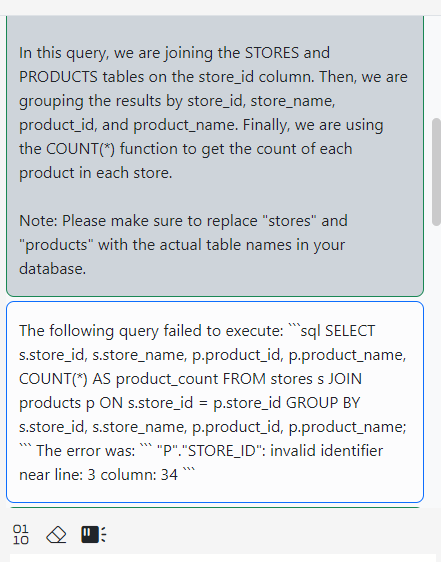
The AI produces the following query:
SELECT s.store_id, s.store_name, COUNT(p.product_id) AS product_count FROM stores s LEFT JOIN products p ON s.store_id = p.store_id GROUP BY s.store_id, s.store_name;
This query is wrong because there is not relationship between the STORES and the PRODUCTS table. Executing the query using the Execute menu button produces an error that is visible in the SQL Pad’s error tab.
Note the new red button that showed up in the menu. Gitora detected that the query did not run successfully and displayed the “Send Error to AI” button. Click this button to inform the AI about the error. Gitora will automatically package the query and the error and send a message to the AI on your behalf.
Using the AI Assistant to Analyze Errors
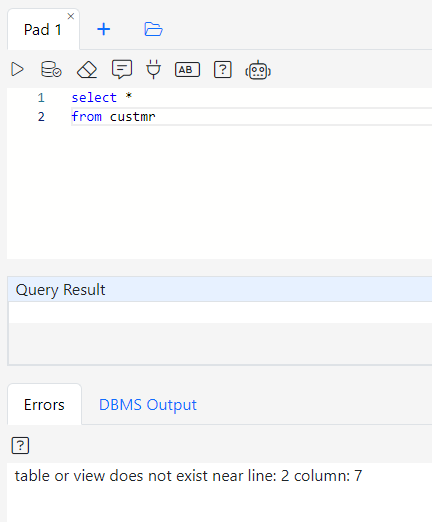
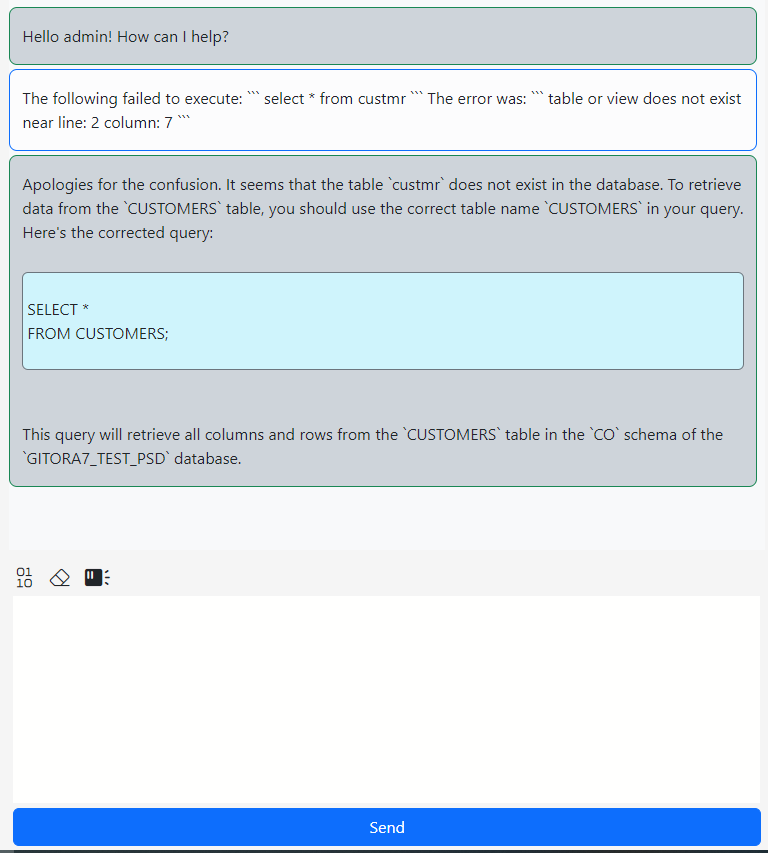
The Gitora AI Assistant can also be used to analyze errors during SQL, PL/SQL execution.
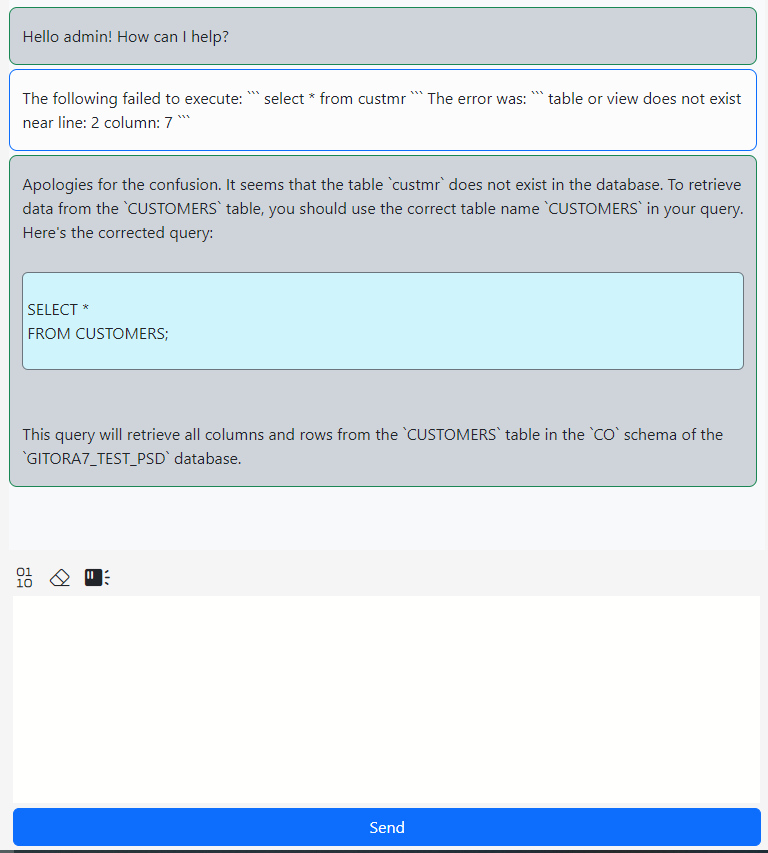
In the screenshot below, I wrote a simple query but misspelled the table name.
Clicking the question mark button under the Errors tab sends the error message along with the text (or the selected text) in the SQL pad to the AI Assistant like so:
Using the AI Assistant to Explain Queries
The AI Assistant can also be used to explain SQL queries (and PL/SQL blocks.)
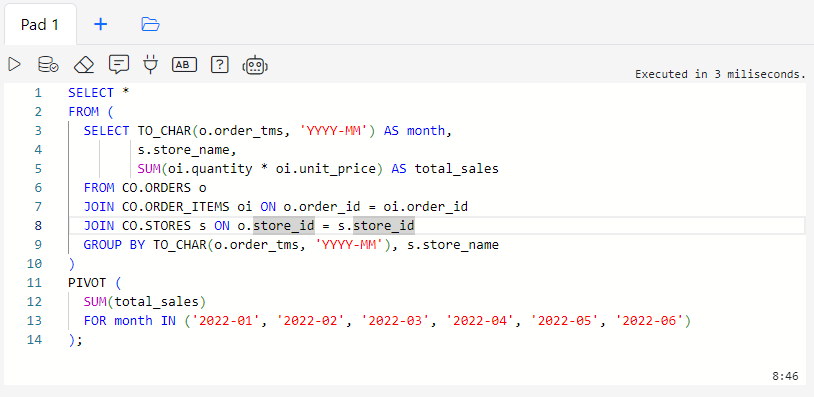
In the screenshot below , the SQL pad contains an SQL query with the PIVOT command.
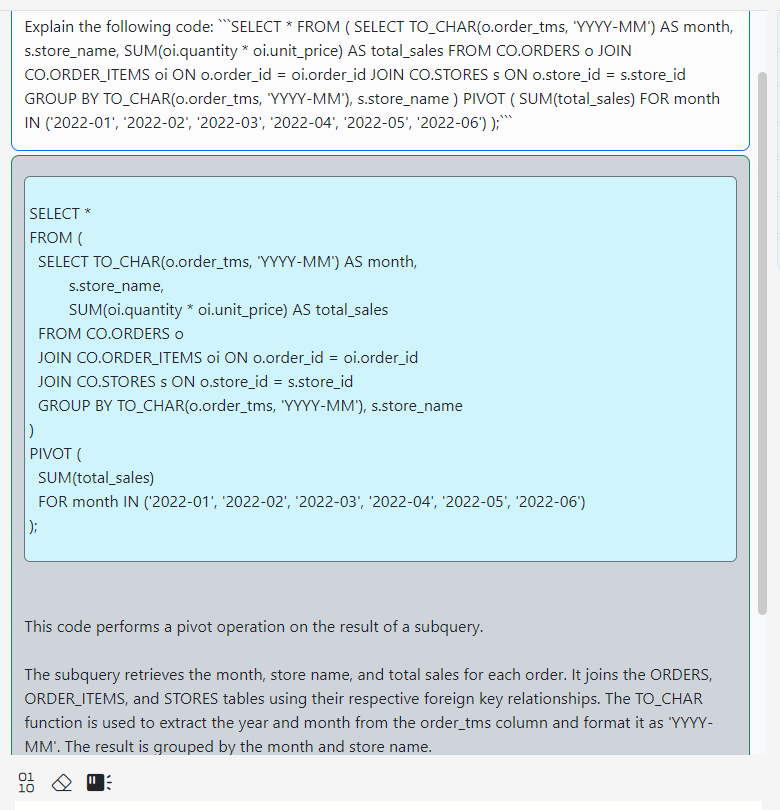
Clicking the question mark button in the toolbar will send a message to the AI Assistant asking it to explain the code.
These are just a few examples about how you can use the Gitora AI Assistant and its schema-aware capabilities. OpenAI GPT models are very capable and I am sure you will come up with many more use cases.
This article explains how to configure and use the Gitora AI Assistant.
Create an OpenAI Account
Gitora AI Assistant uses OpenAI GPT to suggest PL/SQL code, functions, procedures and SQL in real time, right from the editor. Therefore it requires an OpenAI account and subscription. The OpenAI subscription is on a pay-as-you-go basis and is extremely affordable. To give you a rough idea, during the development of this feature I’ve spent about a dollar a month to use the OpenAI API’s.
After you create your account, go to Manage Account -> Billing -> Payment Methods and enter your credit card information. You will only be billed for what you use.
Generate an API Key
Finally, generate your API Key. You will enter this key to the Gitora PL/SQL Editor so that it can start making suggestions while you code.
Start The Gitora PL/SQL Editor
From the home screen, register a database and a database user if you have not already done so. To learn how you can register a database and a database user please read Getting Started with the Gitora PL/SQL Editor.
Click one of the connect buttons in the home screen. The PL/SQL Editor will open in a new tab.
Note the new AI icon on the toolbar of the PL/SQL Editor.
Click the small arrow text to the AI icon. The AI Assistant Settings button will show up.
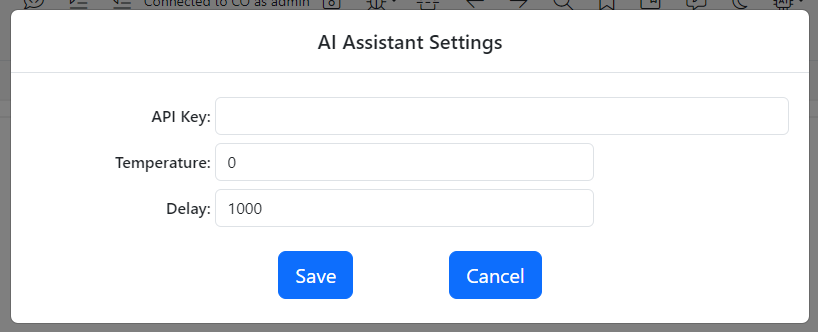
Click the button. The AI Settings dialog will show up.
Enter your Open API Key to the API Key field.
The settings dialog has two more parameters:
Temperature: This is the setting that tells the AI how creative it should be while making suggestions. It accepts any value between 0 and 2. In my experience, 0 worked best but feel free to experiment with different values.
Delay: The AI Assistant makes suggestions when you stop typing. This is the amount of time it waits in milliseconds, before it starts the process to come up with a suggestion. 1000 milliseconds may be a little bit on the higher end depending on your style. I recommend you to experiment with lower values such as 500, 250 etc…
The shorter the delay, the more requests Gitora will make to the OpenAI API, meaning you will spend more money. The API is extremely affordable though so I don’t think this will be an issue but I thought I’d mention it. At the time of the writing of this tutorial, the API costs about $0.002 per 1,000 tokens. 1000 tokens is about 750 words. Again, for reference, I spent about a dollar a month while building this feature.
After you are done with the AI Settings Dialog, click save.
The AI icon should turn black on the toolbar to indicate that the AI is on. (or if you are in the dark mode, the icon will turn white.) If it is not turn on, click the AI icon to enable it. Clicking the icon again will disable the AI Assistant.
From this point on, by default, the AI Assistant will be enabled whenever you open a new PL/SQL Editor as long as you have a registered OpenAI API Key.
If you’d like to remove your OpenAI API Key, enter a space character as the API Key in the AI Assistant Settings dialog and click save.
Using the Gitora AI Assistant
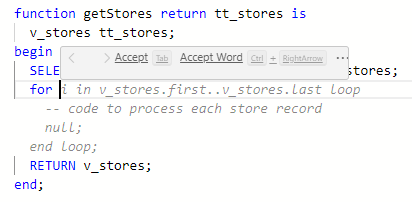
Open a package or any code object and start coding. You can also open an SQL Pad. When you stop typing, the code suggestions of the AI Assistant will show up as lightly colored text in the editor. Click the tab button to accept the code suggestion. If you’d like to accept just a part of the suggestion, hover over the suggestion. A small dialog window will pop up.
Using this dialog, you can accept individual words in the suggestion.
Gitora Editor includes a PL/SQL debugger. For the PL/SQL debugger to work, the database session being debugged must be able to access the debugger. This requires you or your DBA to open a port or a range of ports in your Oracle database. To achieve this, follow the steps below:
Execute the script at gitora/GITORA_DEBUGGER_ACL_SCRIPT.sql in the zip file, for every database user that you’d like to use with the debugger. The script is a very small PL/SQL code block:
Replace the [ORACLE_USER_NAME] in the text above with the actual name of the Oracle user that you want to be able to use with the debugger and execute the script. Run this script once for every Oracle user that needs to be able to connect to the debugger.
Change the start and end port numbers (both inclusive) as you see fit.
Update the following parameters in the Settings.properties file.
debug.port.range.start: Set this value to the same value you used for the lower_port input parameter.
debug.port.range.end : Set this value to the same value you used for the upper_port input parameter.
debug.server.ip: This is the IP address of the Apache Tomcat server that is running the Gitora Editor web application. This is NOT your desktop’s IP address (although it could be if you are running Gitora locally.) This IP address will be used by the Oracle database session to be able to find and connect to the Gitora debugger.
Below is an example of how the three parameters are set:
This tutorial explains how to use the PL/SQL debugger that comes with the Gitora PL/SQL Editor.
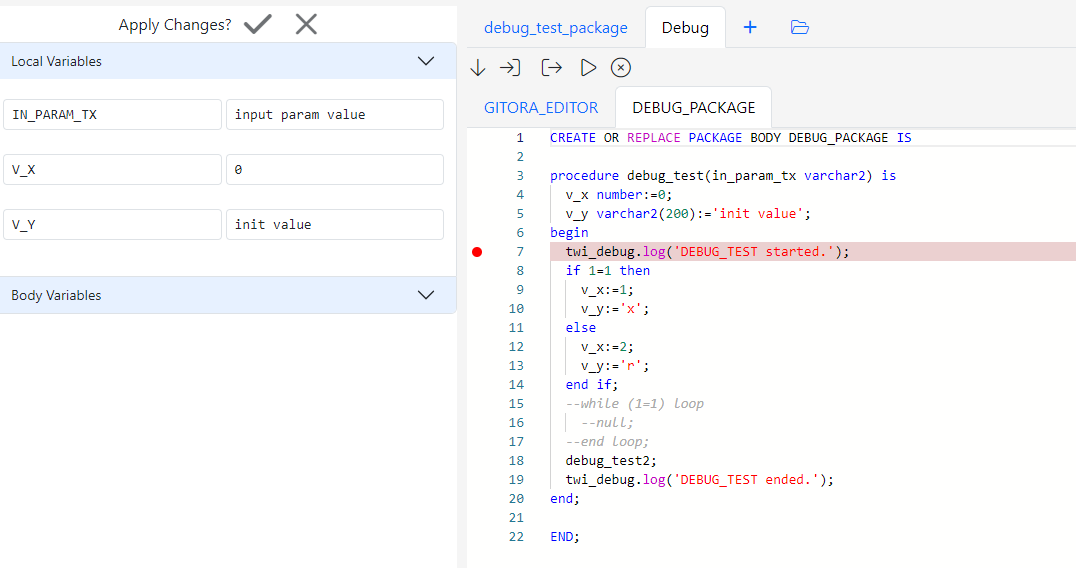
Open a database object in the editor. Next, click the debug icon in the editor to activate the debug mode.
The icon changes color. The change of color indicates that the open database object (in our example, a PL/SQL package), is now compiled in debug mode. As long as the debug icon has color, every save you make will compile the object in debug mode.
Click left of the line numbers to create a breakpoint. Click again to remove the breakpoint.
Create a new SQL Pad to run the procedure/function with the breakpoint.
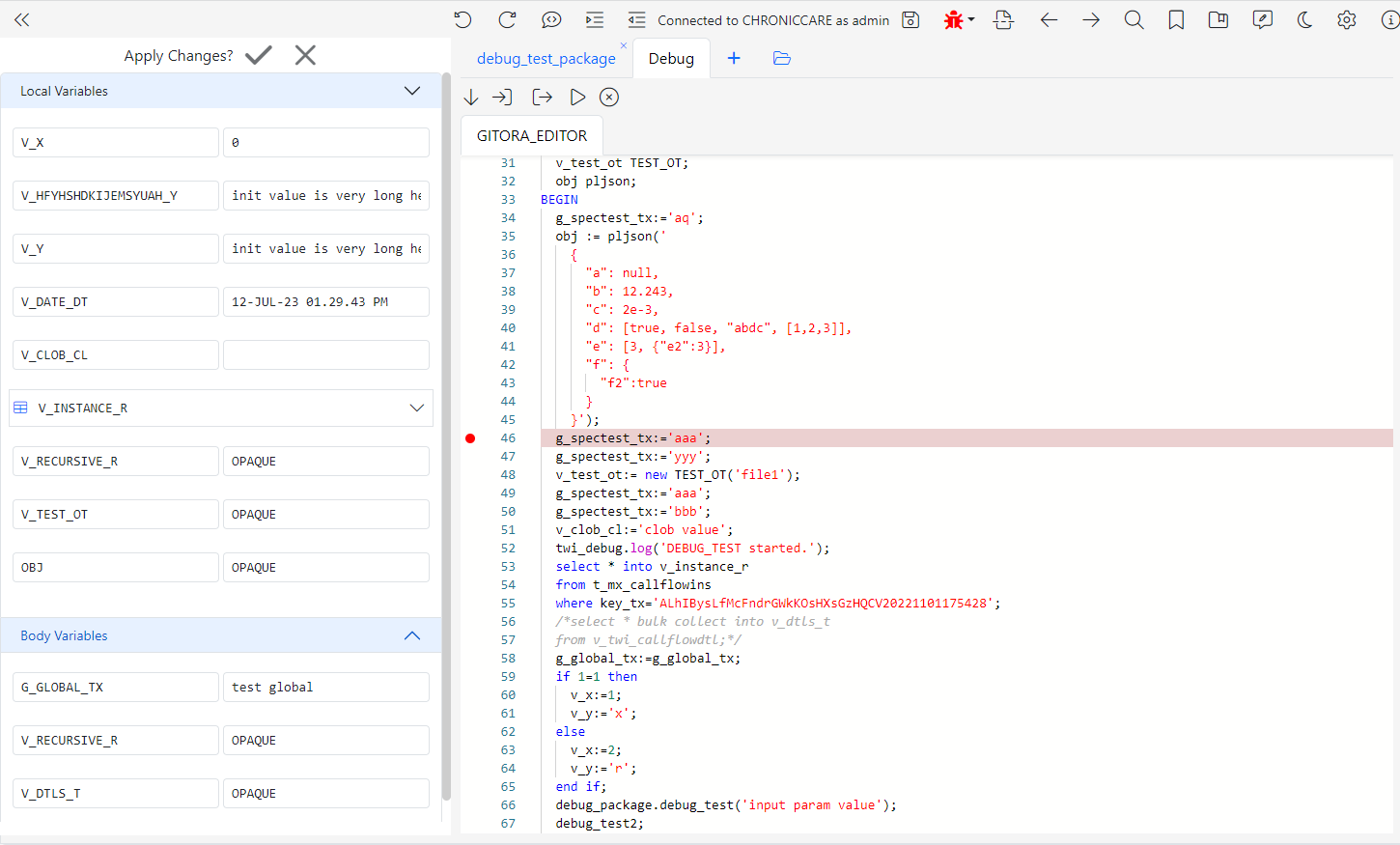
Click the Run button to execute the PL/SQL code block. The execution will stop at the breakpoint. The Debug Tab will show up.
On the left side of the editor, you can view the current parameters and their values. Please note that, Oracle does not provide support to view the values of every variable type.
In the middle of the screen, you will see that the execution has stopped at the breakpoint. You can add additional breakpoints, or remove existing ones while debugging.
The debug tab toolbar has five buttons that should be familiar to all programmers. From left to right, you can Step Over, Step In, Step Out of each line of code. The forth button is to resume the execution until the next breakpoint. If there are no breakpoints, the PL/SQL block will execute until completion. The final button suspends all breakpoints for the duration of one execution.
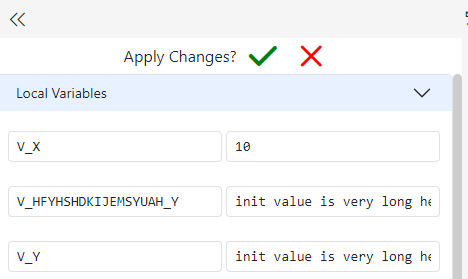
Changing Runtime Values of Variables
Gitora PL/SQL Debugger enables you to change the values of PL/SQL variables during runtime. To change the value of a variable, simply update its value on the left of the screen. To apply your changes to the execution, click the checkbox button at the top of the current parameters view.
Click the X button if you’d like to revert the changes you made to the variable values.
Adding Breakpoints to Multiple Database Objects
In our example, the GITORA_EDITOR.DEBUG_TEST procedure references other procedures, for example the DEBUG_PACKAGE.DEBUG_TEST procedure. You may want to add additional breakpoints to those procedures as well.
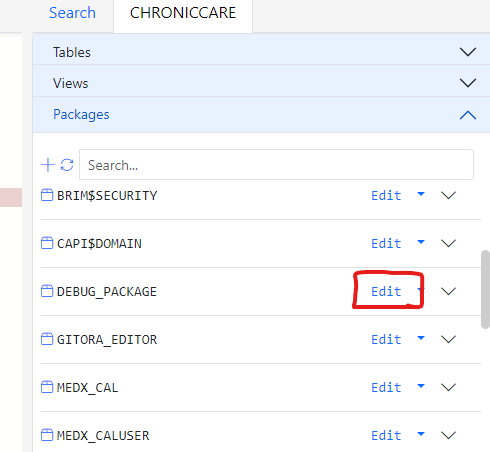
To achieve this, locate the procedure in the Schema Navigator and click edit as shown below.
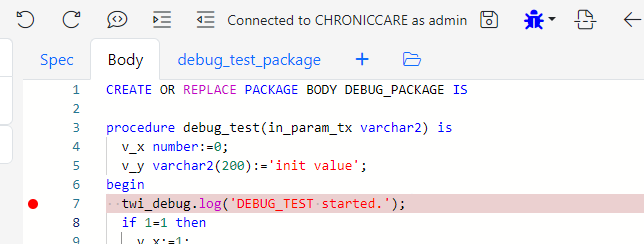
The package opens in another browser tab. Since we activated the debug mode, the new tab is also opened in debug mode. Therefore, the DEBUG_PACKAGE is already compiled in debug mode.
Set a breakpoint in the DEBUG_TEST procedure. Go back to the first browser tab and run the PL/SQL block again.
First, the execution will stop at our initial breakpoint. Click the resume button and the execution will stop at the new breakpoint we created in the DEBUG_PACKAGE.DEBUG_TEST procedure.
Joining a Debug Session
It is also possible to join an existing debug session if you already have a PL/SQL object open in an editor.
Lets assume that we already had the DEBUG_PACKAGE open and would like to add a breakpoint.
Click the triangle icon to the right of the debug button. You will see an additional button
Click Join Existing Debug Session button. The Open Debug Sessions dialog shows up.
Click on the “Debug Session Red” button and the package will become part of your debug session.
Multiple Debug Sessions
Gitora Editor can manage multiple debug sessions concurrently. Each debug session is identified with a unique color for the debug icon. For example, all tabs with a red debug icon belong to the same debug session.
To create a new debug session, open two database objects in separate tabs as shown below
In the GITORA_EDITOR tab, click the debug icon to make it red (if it is not already). In the DEBUG_PACKAGE tab, click the same debug icon. The debug icon will turn blue indicating that the DEBUG_PACKAGE is in a different debug session than the GITORA_EDITOR.
Breakpoints are only visible to the debugger if they are in the same sessions. For example, in the setup above, breakpoints you will create in DEBUG_PACKAGE will not be visible to the other tab that has the GITORA_EDITOR open, because that tab is in a different debug session.
In the Gitora Editor Home, click the Connect button next to an Oracle username to open the Gitora PL/SQL Editor in a new tab.
The PL/SQL Editor shows up with an empty SQL Pad that uses the Oracle user you clicked, as its default connection information. The database object browser on the right shows the database objects in the Oracle user you clicked.
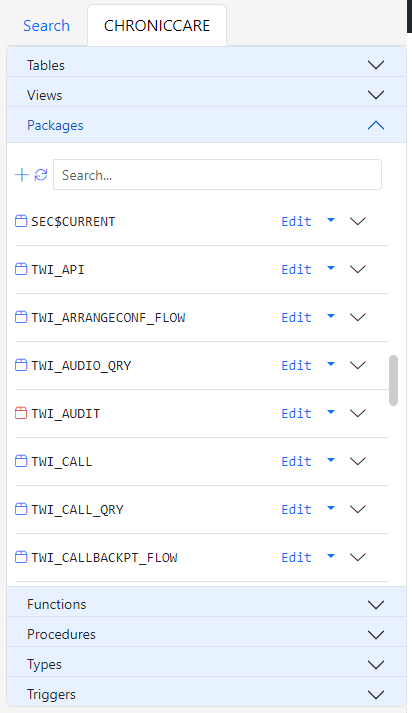
Expand the Packages Accordion in the object navigator. The list of packages in the schema will show up. Click the Edit button next to a package.
The Gitora PL/SQL Editor opens the package spec and body in the current browser tab. The editor will open any subsequent database object in a new browser tab.
Before we start editing, let’s go over the list of buttons and features in the editor.
The Toolbar
The toolbar is always at the top of the screen. Below is the list of buttons in the toolbar from left to right and a brief description for each one:
Show/Hide Method List
The Gitora PL/SQL Editor shows a powerful content navigator when a package or an object type is displayed in the editor. This button hides/shows the content navigator. It can be used to create more space for the PL/SQL editors and the SQL Pads.
Undo/Redo
Use these buttons to undo/redo changes you made in the current editor. Since a package and an object type have two editors, one for the spec and one for the body, these editors have separate undo queues.
However, if an editor is split in two using the split editor feature. The split editors share a single undo queue.
Comment Out/In
Select a block of code and click the Comment button to turn it into a block of comment. Conversely, select a block of comment and click the same button to turn the comment to a code block. This feature uses the — notation to create comments and similarly can reverse comments that start with –.
Indent
Select a code block and click the Indent button to shift the block 1 tab size to the right.
Outdent
Select a code block and click the Outdent button to shift the block 1 tab size to the left.
The Context Label
The context label in the middle of the toolbar displays the Oracle username and the database you clicked to open this tab as well as your Gitora Editor user name.
Save
Used to save the changes made to the database object open in the editor. The icon turns dark if there are changes to save.
Split Editor
Splits both the spec and the body editors in two horizontally. The icon turns dark if it is active.
Back/Forward
These buttons work similar to back and forward buttons in a browser. Gitora tracks the locations your cursor has been to in the editors. Clicking the back button takes your cursor to the previous location it was. Conversely, clicking forward button takes the cursor back to the next location.
Find and Replace
The Gitora PL/SQL Editor has a powerful Find&Replace widget that you can use to search for letters, whole words and replace them. You can even search using regular expressions. Clicking the icon the first time displays the widget. Clicking it the second time hides it. You can also use CTRL-F to show the widget.
Feedback
Please use the feedback button to share you comments or inform us about bugs and issues.
Color Mode
Click the color mode button to switch between light and dark mode.
Settings
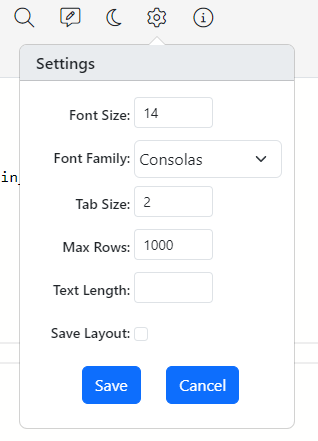
Clicking the settings button displays the settings window.
In this window, you can set the font size, font family, tab size values for the Gitora PL/SQL editor.
Max Rows value determines the maximum number of rows a query you execute returns.
Text Length sets the maximum length of the text the editor returns. If set, longer text values will be cut at the length you specify.
Tick the Save Layout checkbox, if you’d like the Gitora PL/SQL editor to open reusing the widths and heights you set for the MethodList on the left and the Object Navigator on the right.
Click the Save button to store your changes.
About
Click the icon to display the version and build number of the Gitora PL/SQL Editor.
The Workspace
The middle part of the Gitora PL/SQL Editor is your workspace. It consists of three columns. From left to right: the Method List (Package Navigator), the Editors area and the Database Object Navigator.
Each column is separated with a splitter. You can move these splitters left or right to adjust the width each column covers on the screen.
Method List (Package Navigator)
This column displays the procedures and functions in the package or object type that is open for editing in the editor.
The Search Box can be used to filter the methods in the list.
The Refresh button can be used to update the list if any of the new functions or procedures you created is not shown in the list.
The functions and procedures that are both on the spec and the body have a lighter color than the ones that exists only in the body. If a method only exists in the spec, its color is yellow.
Clicking a method name will take the cursor to its location in the active editor.
The Editors
The center of the workspace is where the code editors are. The editor has two types of editors: The PL/SQL editors and the SQL editors.
The Gitora PL/SQL Editor opens the first database object in the current tab. Subsequent objects are opened in new browser tabs.
Both editors provide auto complete suggestions. The default list of suggestions are all the words in the current open database object. After you type a dot character, the editor reads the word left of the dot and shows relevant suggestions depending on whether the word is a schema, a table, a view, a package or an object type. In the picture below, you see the editor recommending a list of method names because the user typed a package name.
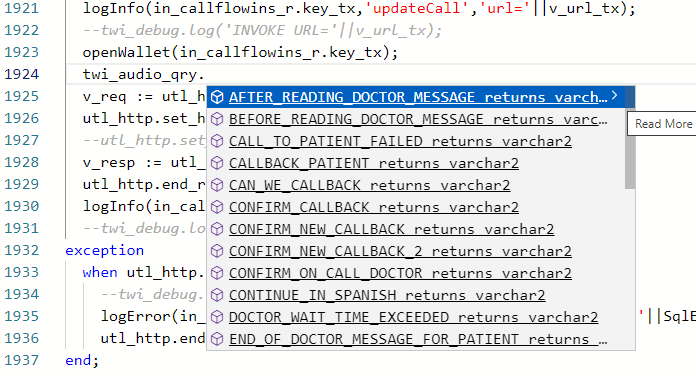
Note the arrow sign > in the upper right corner of the suggestions box. Clicking the sign will expand the highlighted selection to display its full text. Change your selection and the expanded area will change with your selection. This is a toggle you can turn on/off with each editor separately.
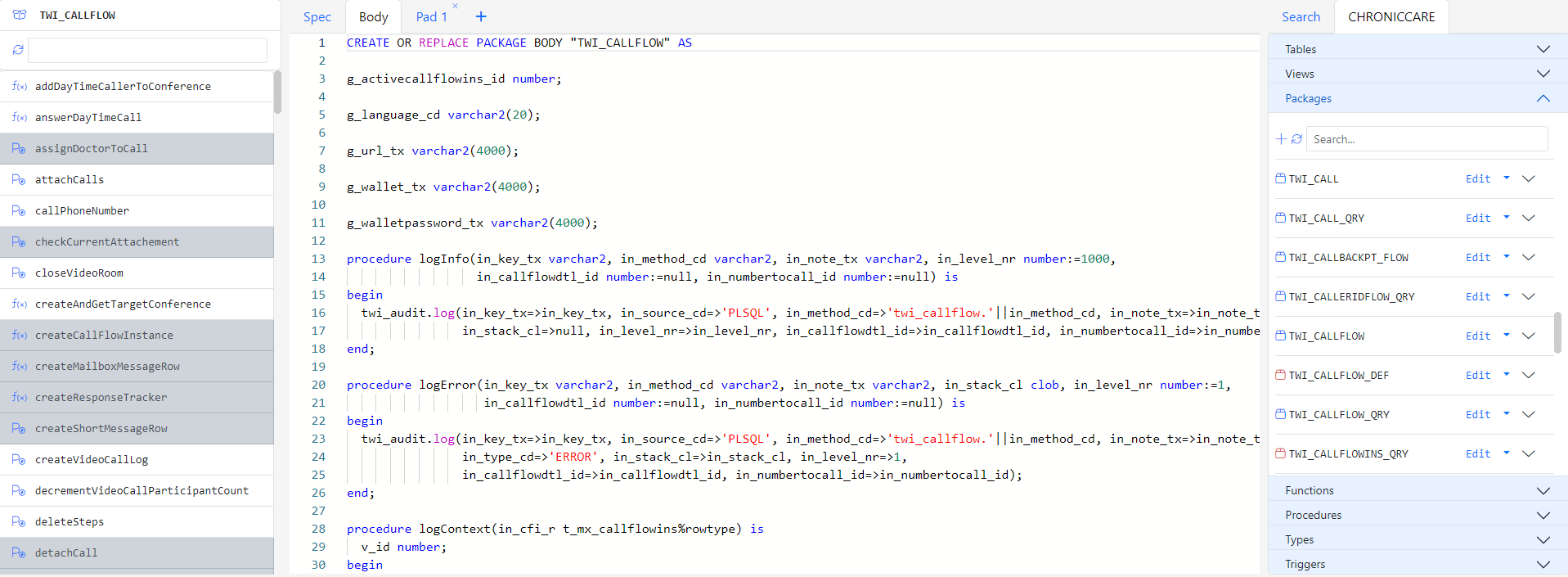
Gitora detects [schema].[package]. syntax and can show suggestions for database objects in other schemas. In the example below, Gitora recommends the methods in the twi_call package which is in the HR schema.
The SQL Pad
Clicking the plus button next to the Body tab, creates a new SQL Pad which you can use to execute PL/SQL blocks, SQL queries, DML and DDL statements. You can create as many SQL Pads as you’d like.
SQL Pads consist of four rows. The toolbar, the worksheet, the query results and the messages rows. Let’s go over these rows one bye one:
The SQL Pad Toolbar
Each SQL Pad has its own toolbar with five buttons. From left to right:
Execute
Click this button to run your SQL statements.
Commit
Use this button to commit your changes. This button works only with a persistent database connection.
Rollback
Use this button to roll back your changes. This button works only with a persistent database connection.
DBMS Output
Use this button to toggle the DBMS Output on or off.
Connection
Use this button to change the current database connection of the SQL Pad.
When you create a new SQL Pad, by default it is connected to the same database user you clicked on to open the Gitora PL/SQL Editor. This connection is not persistent i.e. the Gitora Editor creates temporary database connections when you run the SQL statements by clicking the Execute button.
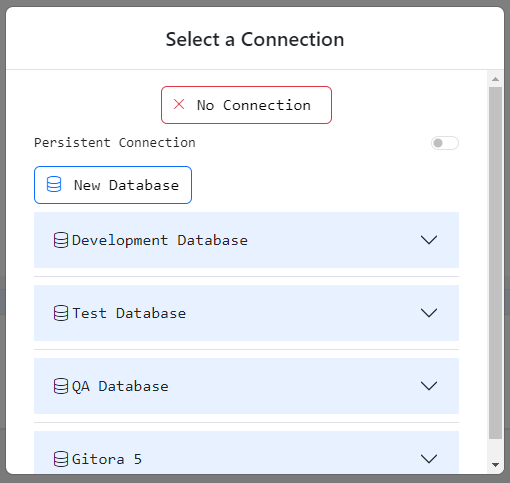
To change the database connection an SQL Pad is using click the Connect button. The database connection selection dialog shows up.
The dialog has the following actions:
No Connection: Select this option if you’d like to disconnect the editor from all database connections.
Persistent Connection: Toggle this button to on, if you’d like the connection you will select to be a persistent connection.
New Database: Click this button if the database you’d like to connect to does not exist as an option. This will take you to the Create New Database screen explained the the Introduction to the Gitora Editor Home tutorial.
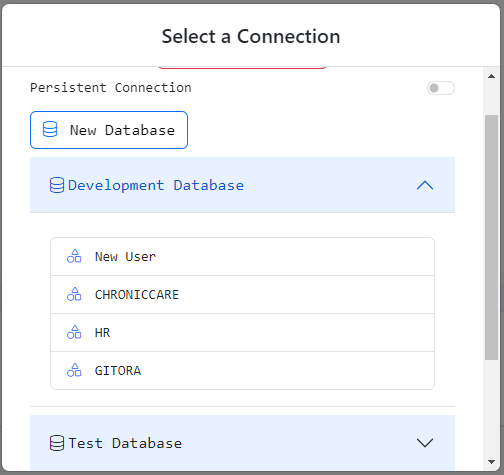
Under the New Database button, you will see the list of databases you can connect. Expand the database you’d like to connect to see the available Oracle users that you can connect to.
Select the Oracle user you’d like the SQL Pad to use and the dialog will close. Your SQL Pad is now using your selection as its connection.
Select New User if you’d like to add a new Oracle username to the registered usernames. Your SQL Pad will use the new Oracle user you will register.
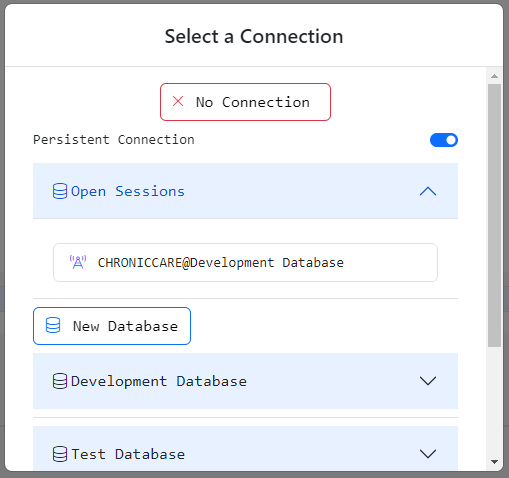
Persistent Database Connections
SQL Pads in Gitora PL/SQL Editor support persistent database connections. To create a persistent connection toggle the Persistent Connection button in the Connection Selection dialog as shown above.
After you select a connection, Gitora will create a persistent connection that the SQL Pad will to reuse every time you execute an SQL statement.
You can also share a persistent connection among other SQL Pads you create. To share a persistent connection:
Create a new SQL Pad.
Click the Connection button.
Toggle the Persistent Connection button to on. A new row titled Open Sessions will show up.
Clicking on the Open Sessions row will display existing persistent connections. Click the one you’d like the new SQL Pad to use and the new pad will share the same database session with the previous pad you created.
Gitora manages the persistent database connections automatically. Closing the last SQL Pad that uses an open database session will close it. Closing the browser tab will also close any unused database sessions.
The file at /gitora/datastore/GitoraEditor/default_pool_properties.json manages several properties that you can edit.
maxSizePerUser property sets the maximum number of open database sessions per user.
timeout property sets the maximum number of seconds a session can remain idle before being closed by Gitora.
timeoutCheck property sets the number of seconds Gitora waits before checking if any session has timed out.
The Worksheet
The worksheet is where you write your SQL statements.
The Query Result
If you execute an SQL query, the results will show up in this row.
The Messages
The messages row has two tabs. The Errors tab shows the errors received while executing the SQL statement in the pad and the DBMS Output tab shows the results of the DBMS Output if there are any. Each SQL pad has its own message row.
The Database Object Navigator
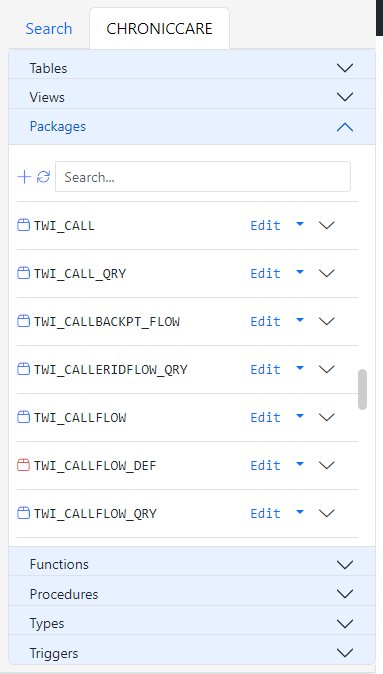
The Database Object Navigator consists of two tabs. The Database Search tab and the Schema Object Navigator.
The schema object navigator shows the seven most commonly used database objects in the database user you are connected to. Just like in the Method List column, you can filter the lists for each object by its name and click the refresh button to display newly created objects.
Selecting and copying an object’s name with CTRL+C copies the objects name in lowercase to the clipboard. The object name is not clickable to make copying easier.
Tables
Each table has a table widget that shows its columns and the foreign keys. Both the column list and he foreign keys can be filtered and refreshed.
In the Columns tab, the column names with a star * indicate primary key columns.
Views
Each view has a view widget that displays its columns.
Each view also has a dropdown button with a list of actions. Clicking the Edit button opens the view in the Gitora Editor (current browser tab or a new tab). You can also Compile and Drop a view.
Packages (Types)
Package and Types work the same way. So we will only go over packages.
Each package has a widget that displays its procedures and functions. Similar to the Method List column, the private methods are in dark color and the public methods are in a light color.
Uncompiled packages have a red icon.
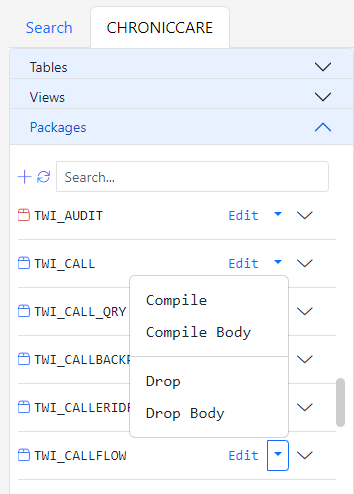
Each package also has a dropdown button with a list of actions. Clicking the Edit button opens the package spec and body in the Gitora Editor. If the current tab already has an open database object, the object is opened in a new browser tab. Otherwise, it is opened in the current tab. You can also compile or drop the spec and the body of a package.
If a package’s spec or body is in an uncompiled state, the dropdown will show the relevant compile action in red.
If a package is missing the body, the compile and drop actions for the body will not show up in the button dropdown.
Functions
Each function has a dropdown button with a list of actions. Clicking the Edit button opens the function in the Gitora Editor (current browser tab or a new tab). You can also Compile and Drop a function.
Procedures
Each procedure has a dropdown button with a list of actions. Clicking the Edit button opens the procedure in the Gitora Editor (current browser tab or a new tab). You can also Compile and Drop a procedure.
Triggers
Each trigger has a dropdown button with a list of actions. Clicking the Edit button opens the trigger in the Gitora Editor (current browser tab or a new tab). You can also Compile and Drop a trigger.
Messages
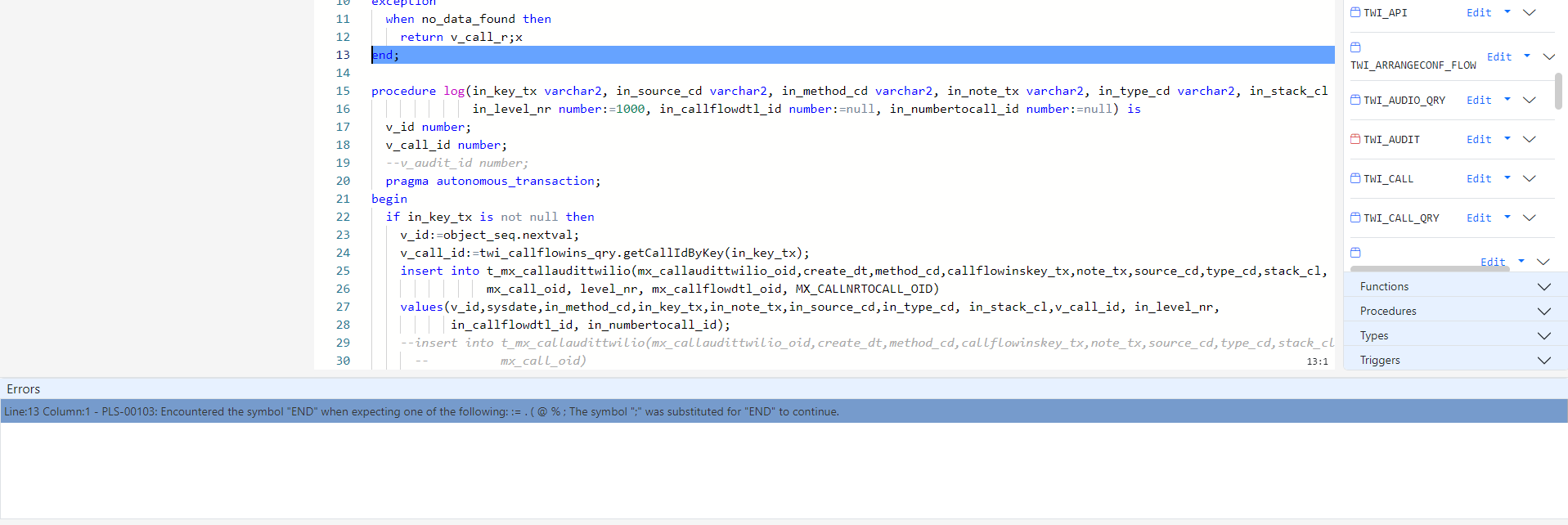
The bottom row in the editor shows error messages received from the database when you save a database object. Clicking an error will take the cursor to the location of where the error has occurred and highlight that row for a few seconds.
Database Search
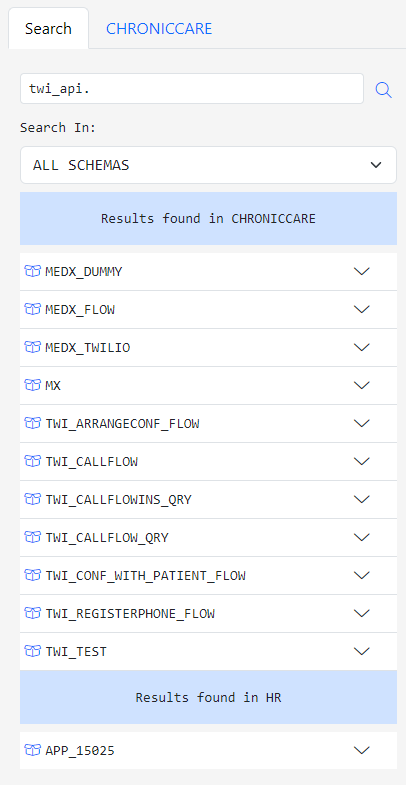
The other tab in the third column of the workspace is the Database Search tab. In this tab, you can search for any text in the entire database code base or only in a schema.
The searches are case insensitive.
The results are grouped by schema and database object.
The icons indicate the type of object that the searched term is found in. The closed package icon indicates a package spec and an open package icon indicates a package body.
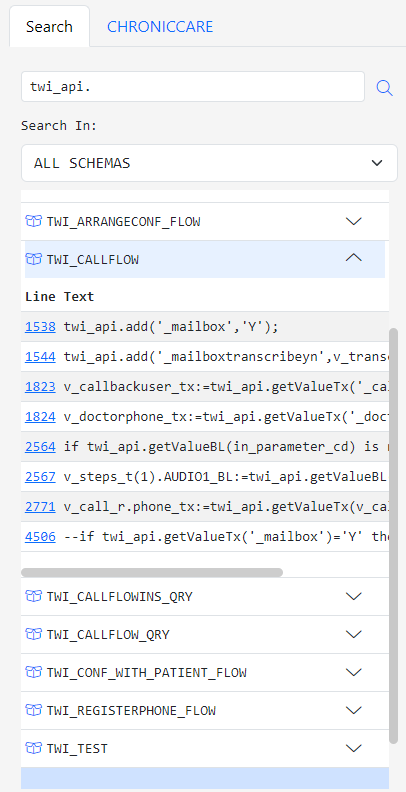
Click on an object to view the lines in the object that contain the searched term.
Clicking the line number will open a new Gitora PL/SQL Editor in a new tab. The new tab will have the database object with the search term open in the editor and the line number you clicked on will be the top line in the editor.