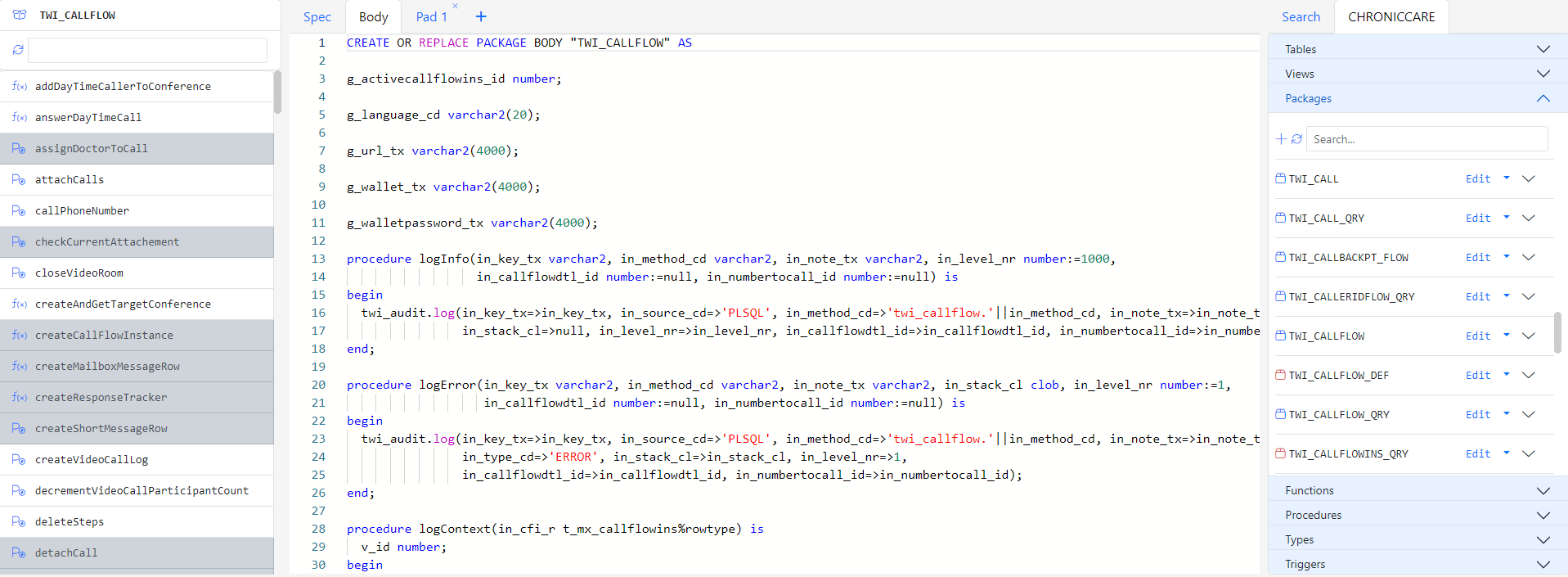
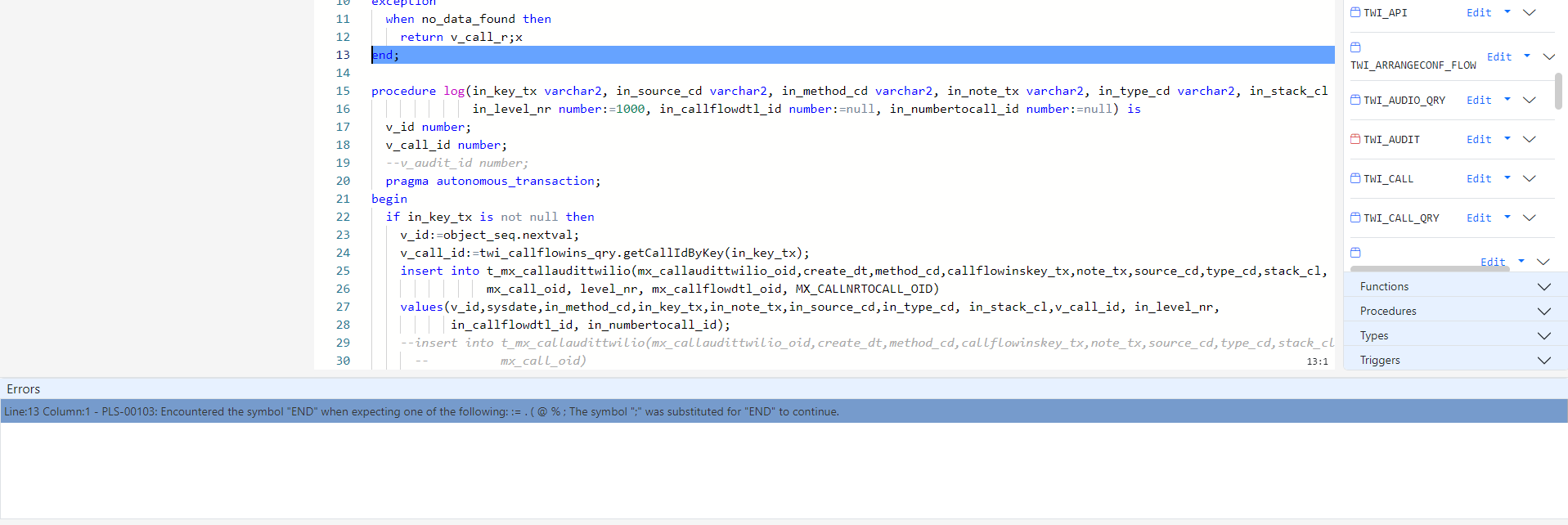
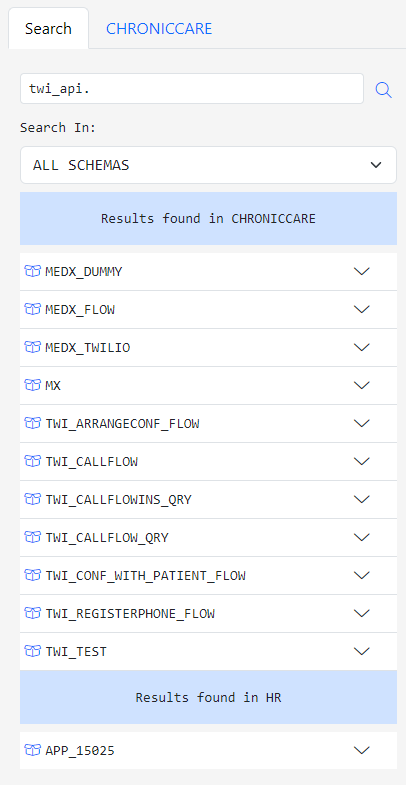
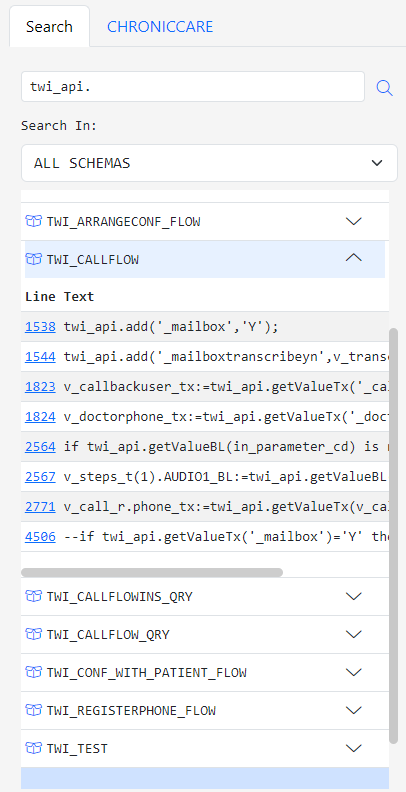
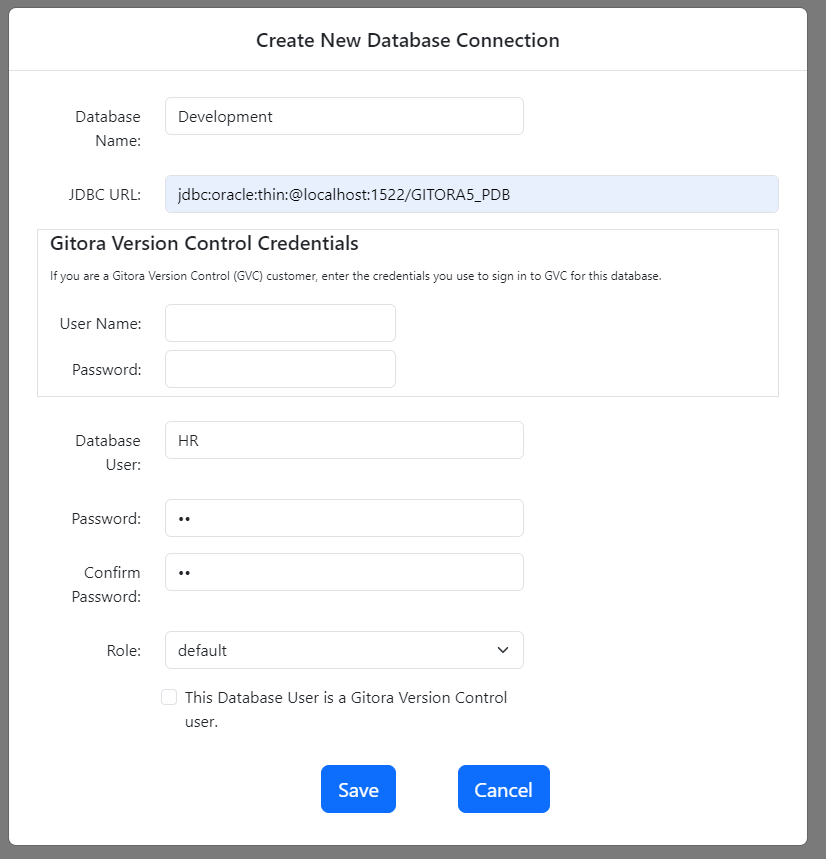
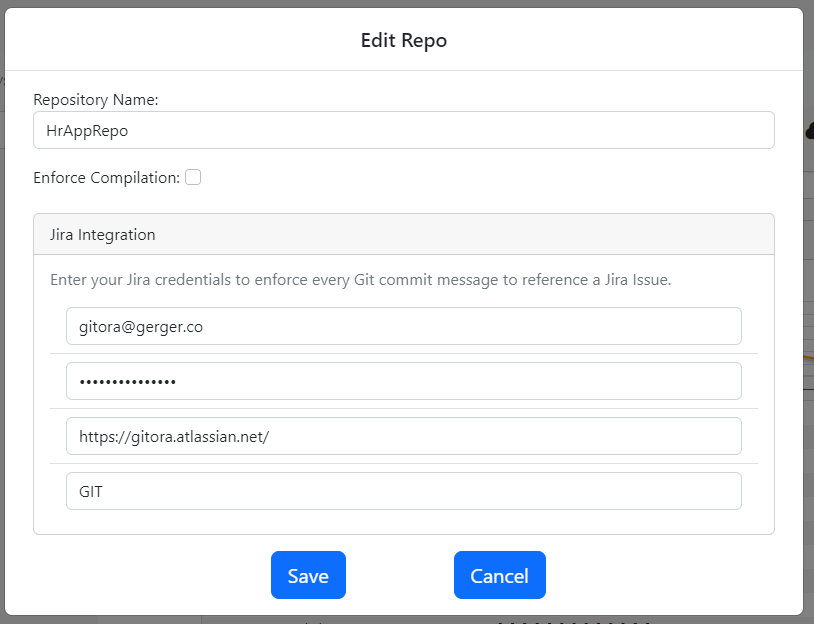
If you have not done so already, please read Getting Started with Gitora For Data to learn how you can create and open repos.
In this tutorial, we will add every table in the Oracle sample schema CO to the CO_REPO, extract the data in the tables, make some modifications to them, issue a git commit and import the data into another database.
Clicking the open button next to the repo in the Home Screen opens the Repo App in a new browser tab.
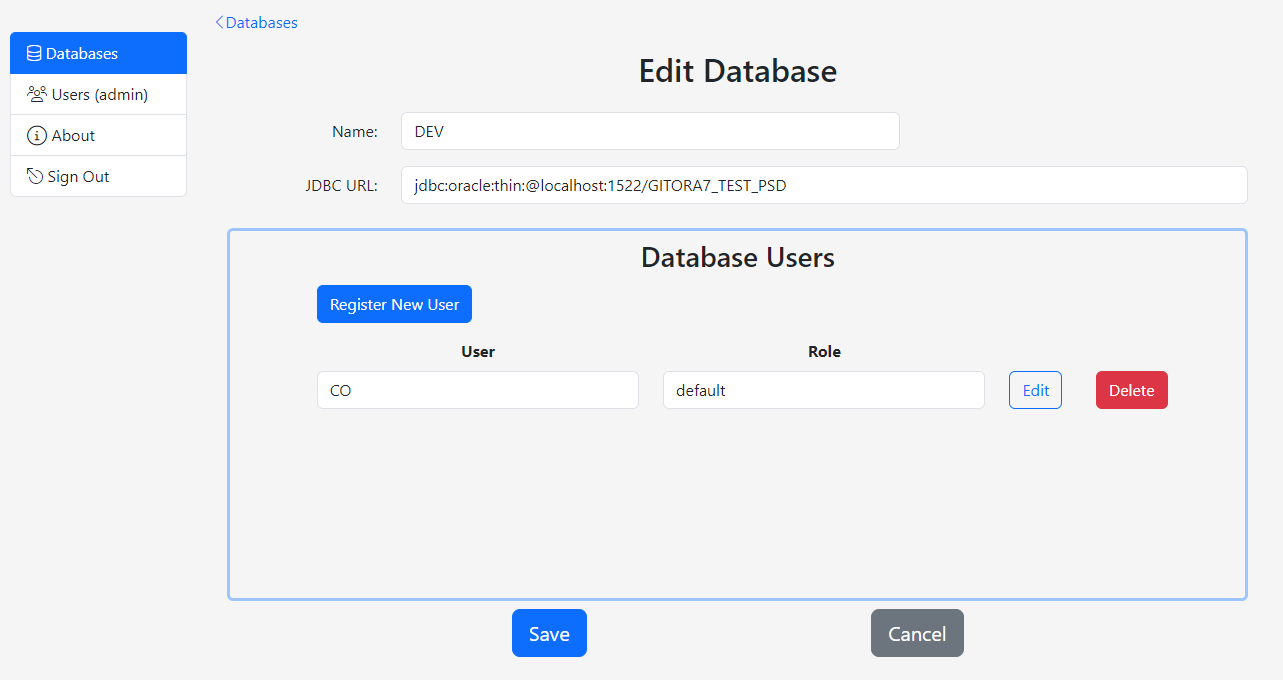
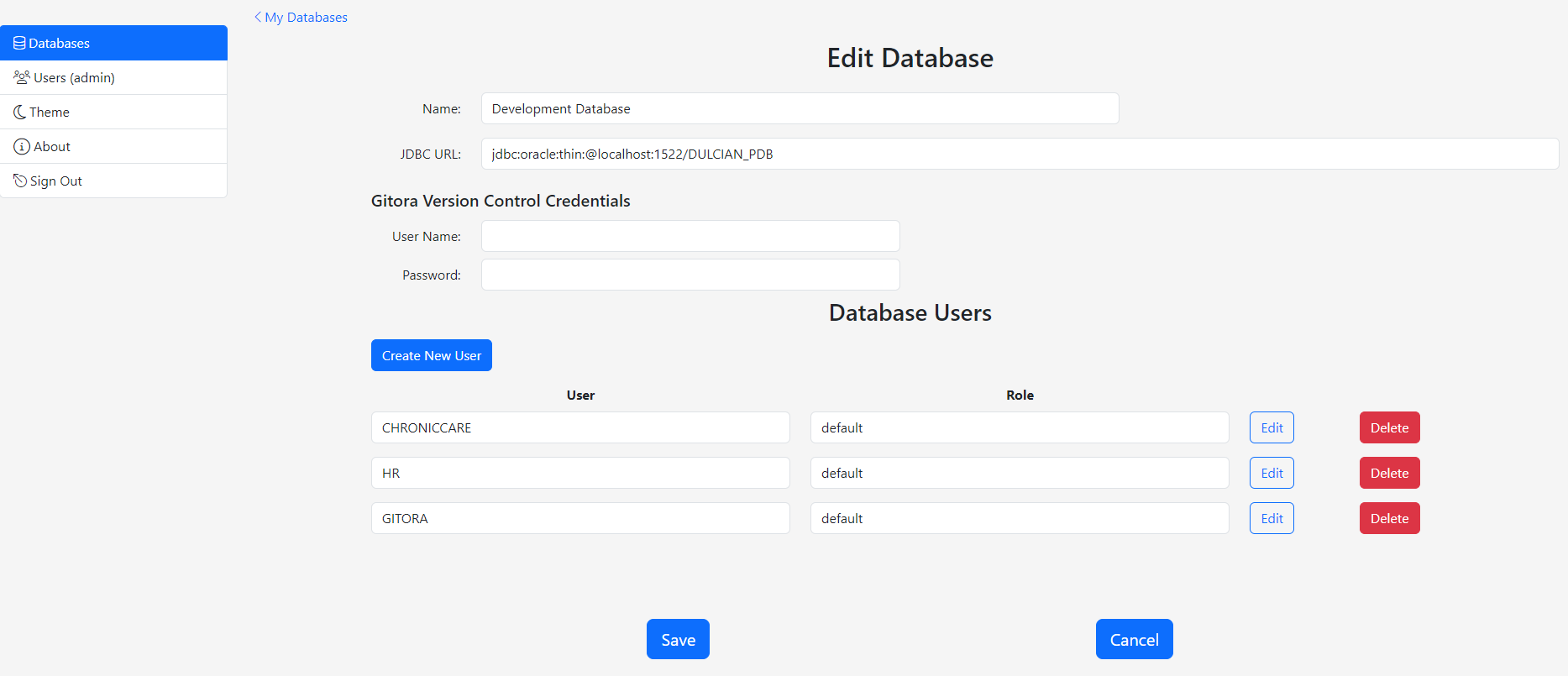
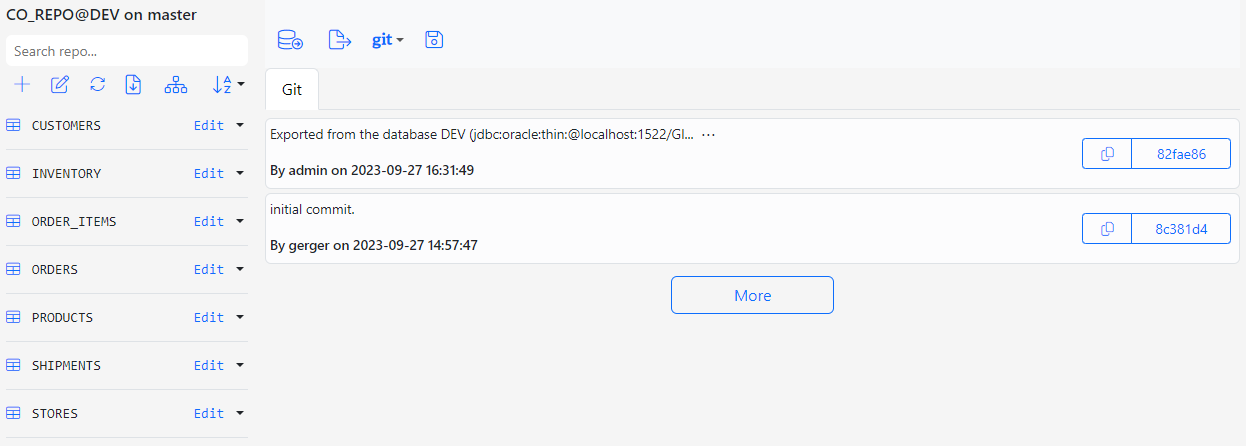
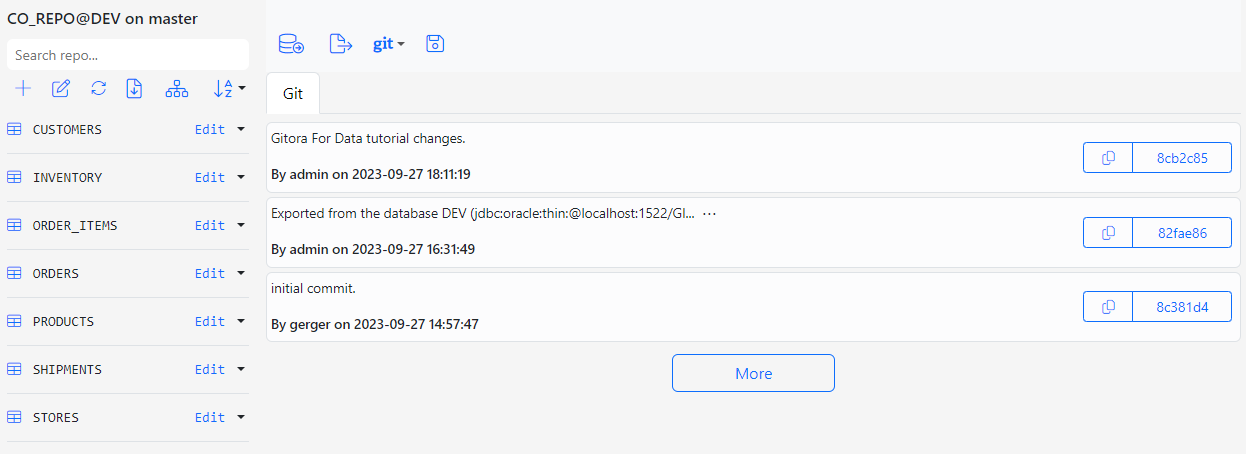
Below is the screenshot of the CO_REPO in its initial state.
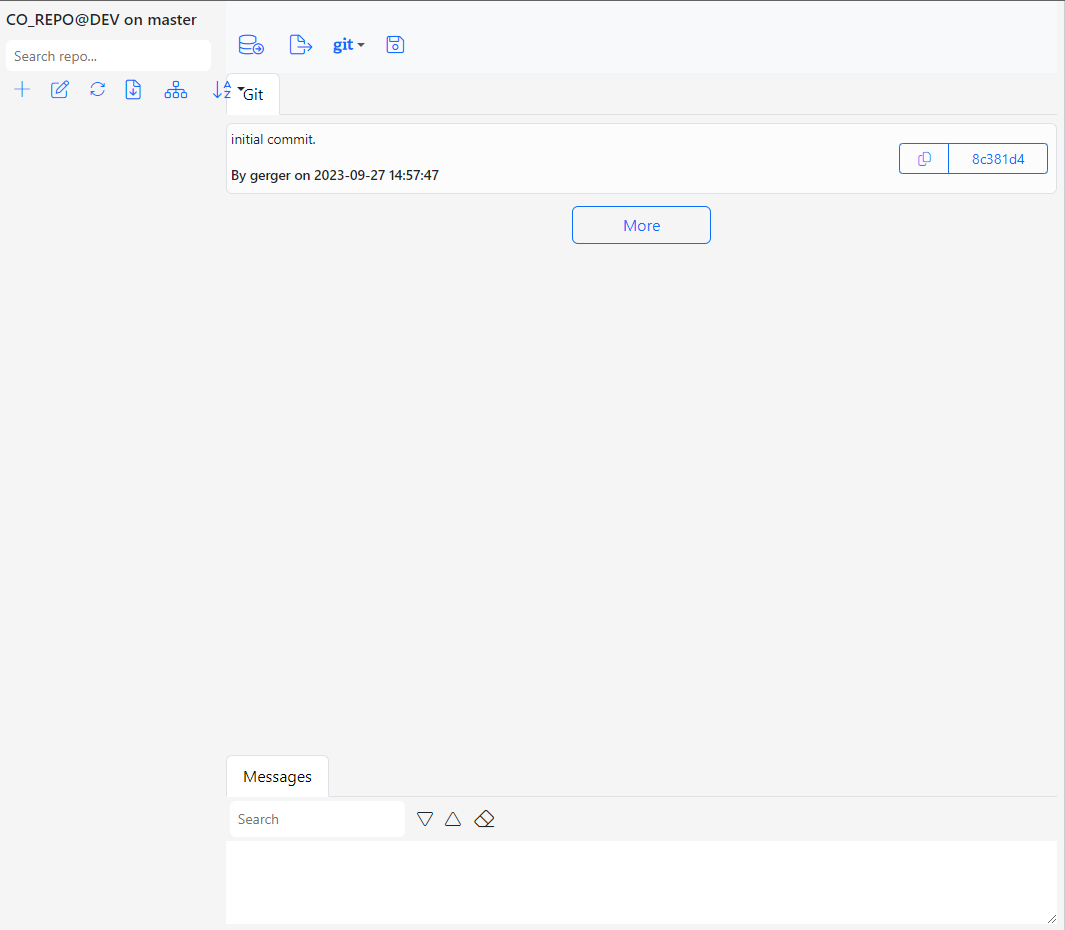
At its initial state, the repo CO_REPO is empty and there is only the initial commit that stored the initial Gitora configuration file.
Following tutorials will focus on other git features such as branching, merging etc…
Creating Entities
To add tables to the repo, click the plus sign on the left of the screen titled under the repo search field.
The Add Table to repo dialog shows up.
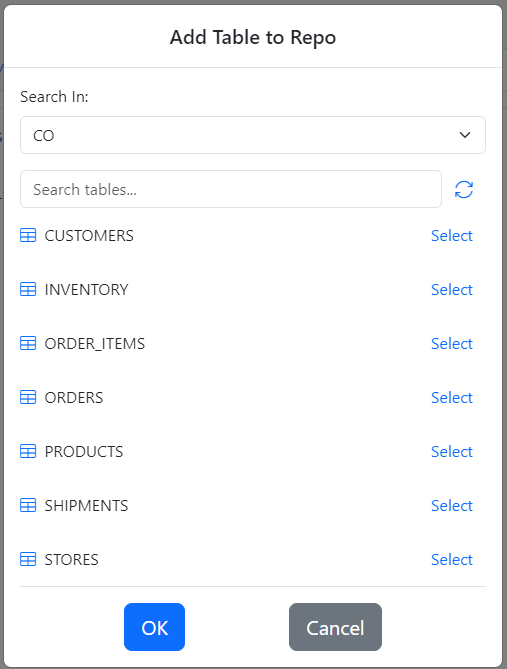
Select every table by clicking the Select button next to each table. Finally, click OK. Gitora will create an “Entity” for each database table. In Gitora parlance, an Entity is an SQL query with a target table. Gitora for Data can export and import entities.
Our repo looks much better now with seven entities.
We’ll talk about entities and what you can do with them in another tutorial. For the purposes of this tutorial, we are ready to export the data out of the CO schema in the DEV database.
Exporting Data to the Git Repo
Click the Export button which is the first button from the left, at the top of the screen.
The Export dialog shows up.
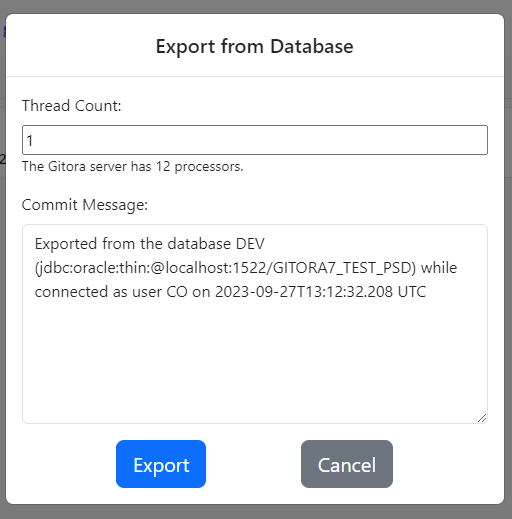
Gitora can export the data in multiple threads in parallel. Gitora displays the number of processors in your server. We recommend picking a number below the processor count as the number of threads to be used for export.
Finally, Gitora adds and commits the generated files to Git. The more files there are the longer this process takes, although JGit is surprisingly fast at adding and committing files.
Enter a Commit Message and click the Export button. A notification will slide in from the right side of the screen, informing you that the export has begun and Gitora will inform you once it is completed. The same message is also displayed in the Messages tab at the bottom of the screen.
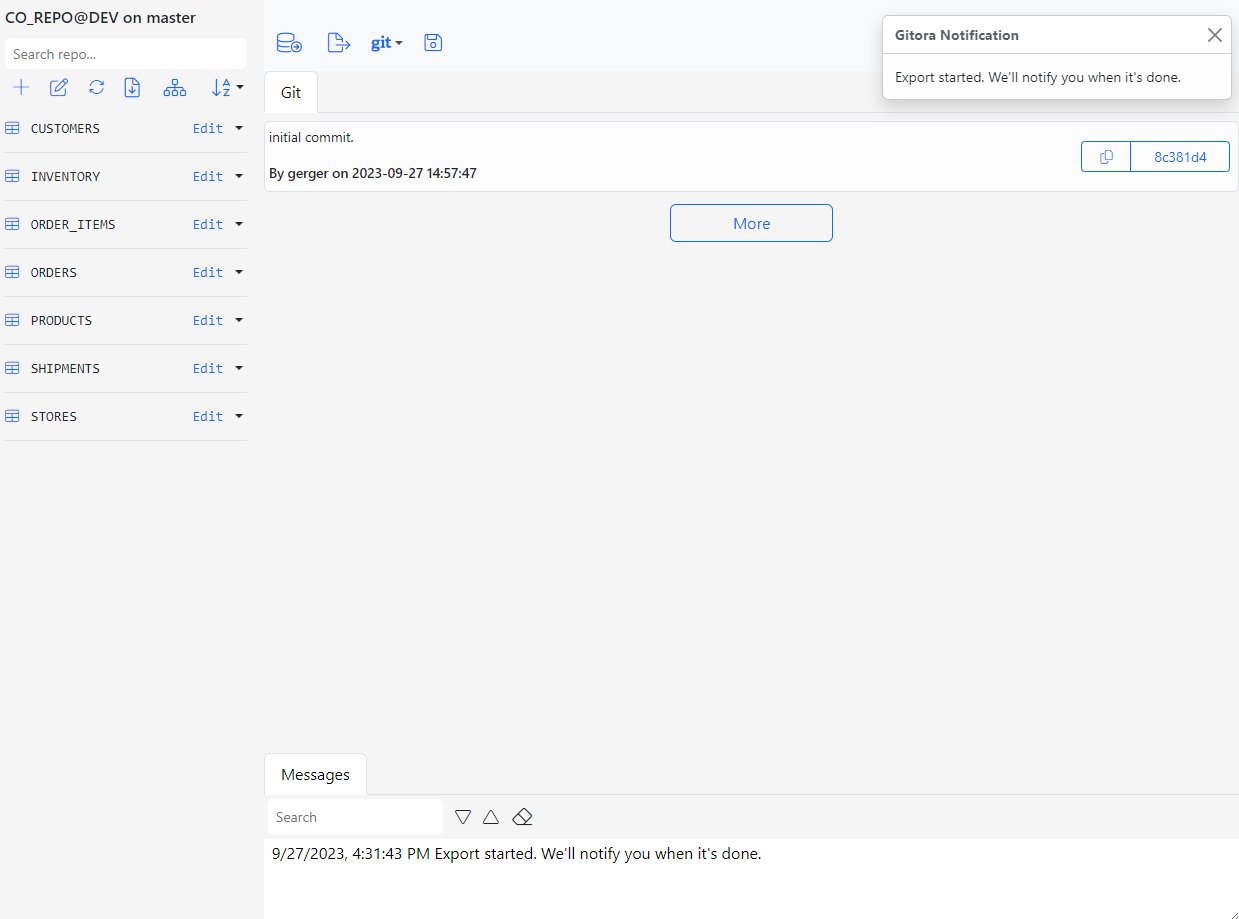
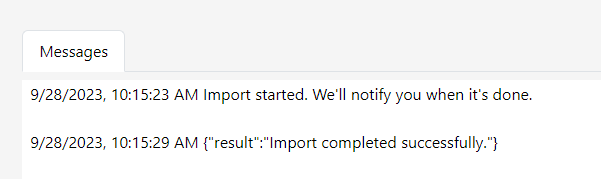
After a short while you will receive a second notification that informing you that the export is completed. The Message tab will also display the same message. The Git tab in the middle of the screen will show the new commit created by the export.
A Word On Export Speed
Gitora is not tested with large datasets and the goal of the product is not to support millions of rows. The CO schema has 8783 rows and Gitora exports the data quickly. Please note that the number of files generated by Gitora can change significantly depending on the File Generation Strategy you choose and the number of LOB columns the tables have.
Browsing the Exported Data
Click on the entity names or open the button group for each entity and select Edit Data to browse the generated JSON files.
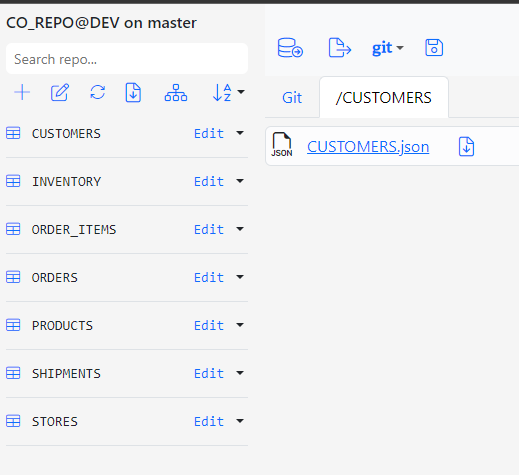
In the screenshot below, we clicked the CUSTOMERS entity to view the contents of the CUSTOMERS folder in the repo’s working directory.
Editing the JSON Documents
To edit the document, click the CUSTOMERS.json link. Click the download icon next to it to download the JSON file.
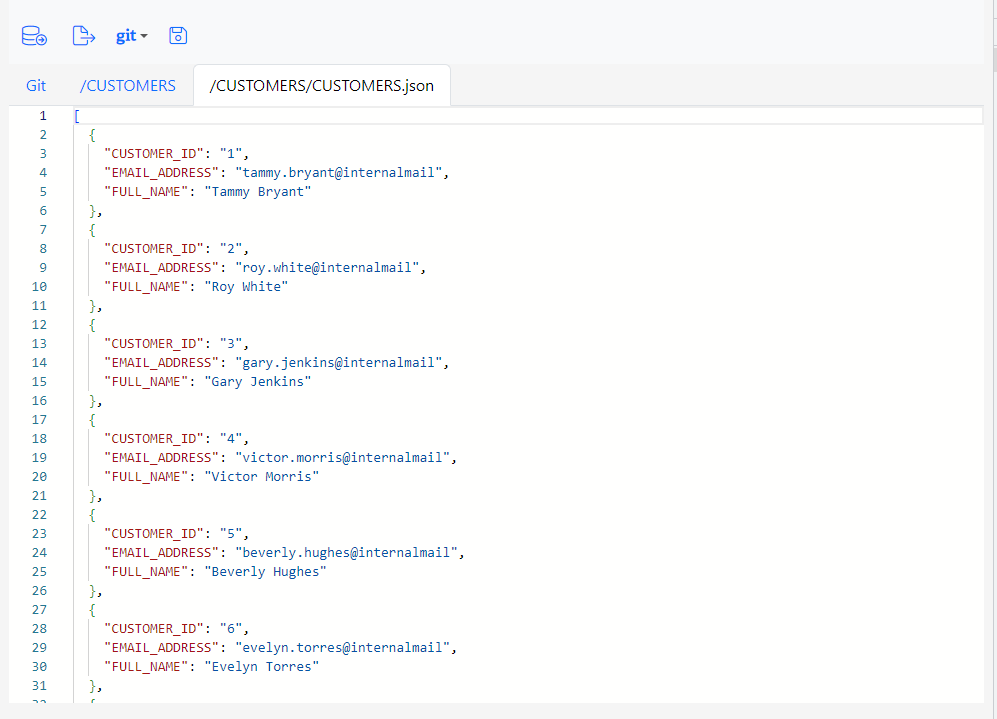
Gitora displays the data in a JSON editor that formats the document properly. Gitora also enforces the JSON syntax for the document. Trying to save the document with a JSON syntax error will cause an error.
For the purposes of this tutorial, change the name of the first customer to John Doe.
Click the Save button at the top menu to save your changes.
Viewing the LOB files
Click the PRODUCTS entity to view the data Gitora exported for products.
The PRODUCTS table contains a CLOB and a BLOB column named PRODUCT_DETAILS and PRODUCT_IMAGE respectively. The PRODUCTS folder contains the files generated for these LOB columns.
As with the JSON documents, you can view the LOB files in the browser (if it is a file type that can be viewed in a browser) or download them.
To view a CLOB file click on the row_o_PRODUCT_DETAILS.txt link. Gitora opens a plain text editor.
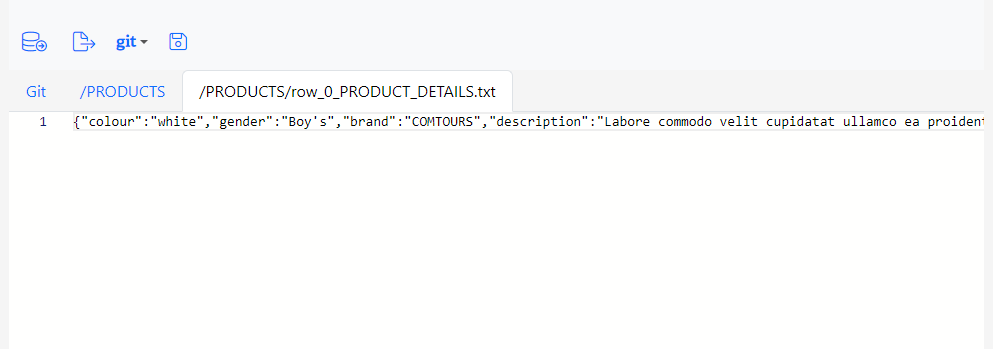
The text data stored in the PRODUCT_DETAILS column happens to be a JSON file (which is confusing for the purposes of this tutorial) but let’s ignore that for a moment. Stored in a CLOB, it could be any kind text data that we are viewing. Since the data is plain text, you can edit it within the Gitora for Data application and save your changes just like you would with a JSON file. Make a change to the file and click save.
To view a BLOB file, either click on the link for the file to view it in the browser or click the download button next to the link to download it.
Unfortunately, the original PRODUCTS table in the Oracle sample schema CO does not contain any BLOB data but we’ve added one for this tutorial.
Clicking the link row_0_PRODUCT_IMAGE.pdf will open the PDF file stored in this file in the browser.
Note that, Gitora can figure out common file types of BLOB data such as PDF’s, PNG’s JPEG’s etc… , automatically.
Committing the Changes
Committing the changes we made to Git is a straightforward git commit. Click the menu item named git at the top of the application and select Commit.
The Commit dialog shows up.
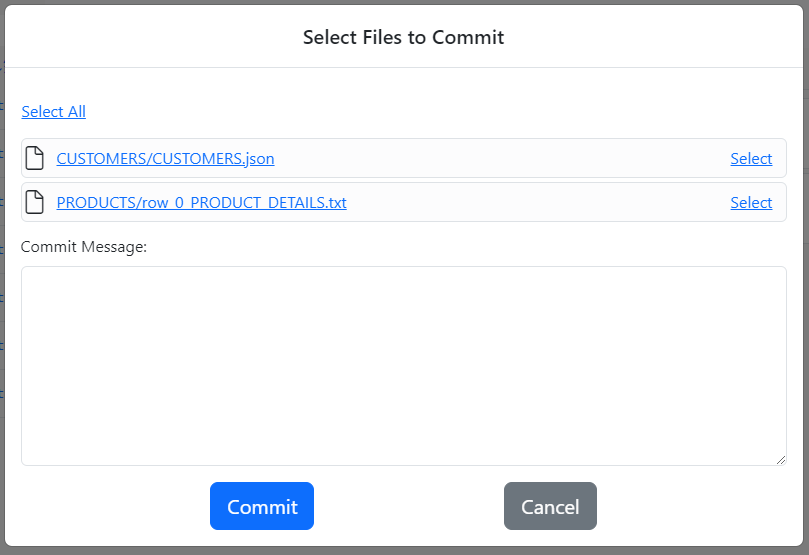
The Commit dialog lists the changed files that can be committed to the repo. Click the name of the file to open the diff editor in a new browser tab that highlights the changes made to the file since the last commit.

Select the files by either clicking Select All or by clicking the Select link for each file. Enter a short explanation to the Commit Message field and click the Commit button.
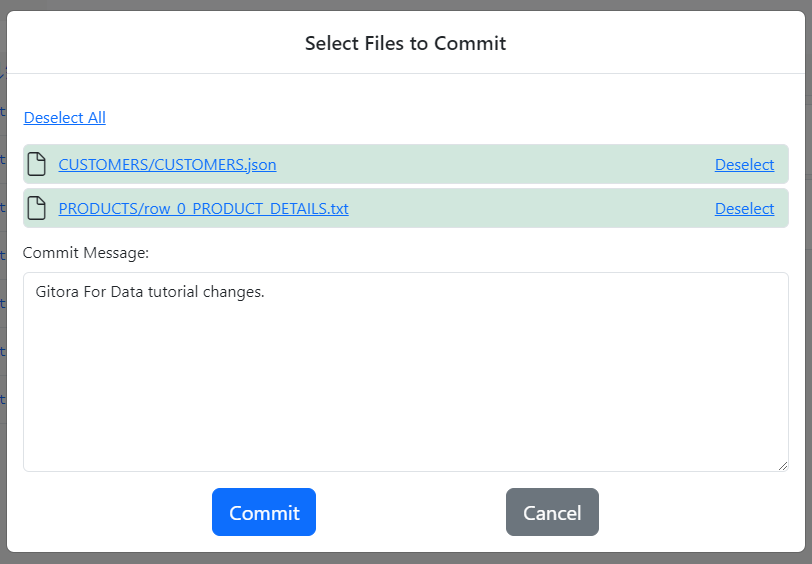
Clicking the Commit button closes the dialog and refreshes the Git tab to display your latest commit.
Ordering Entities for Import
Gitora For Data allows you to set an import order for entities. Click the icon that looks like a hierarchy in the repo menu bar, the second icon from the right among the icons.
The Import Order Dialog shows up.
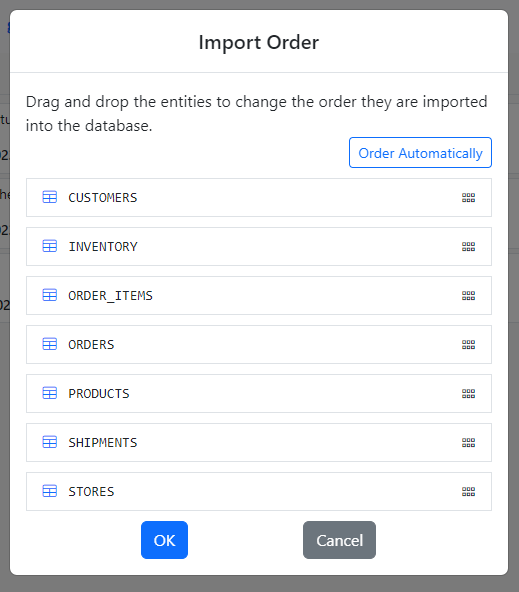
The CO schema has the necessary foreign key constraints to automatically infer the import order. Click the Order Automatically button for Gitora to order the entities.
Not all tables have the foreign key constraints to automatically infer the import order though. In such cases, drag and drop the entity names in the dialog to their correct order in the import. Gitora will start the import from the top of the list.
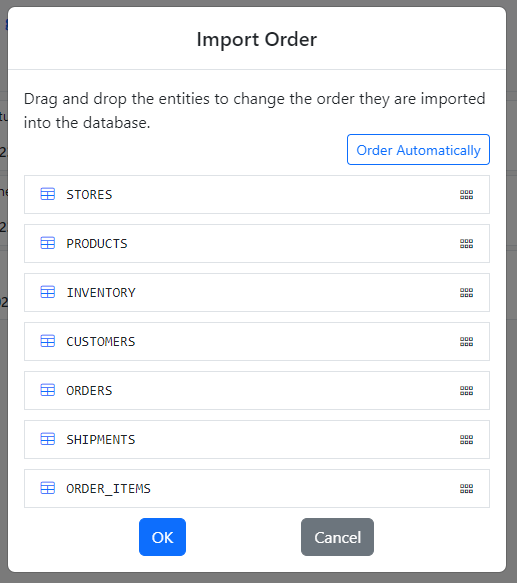
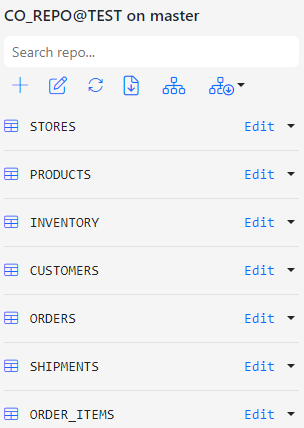
Below is the order of entities after Gitora sorted them automatically. Click OK to accept and save the order.
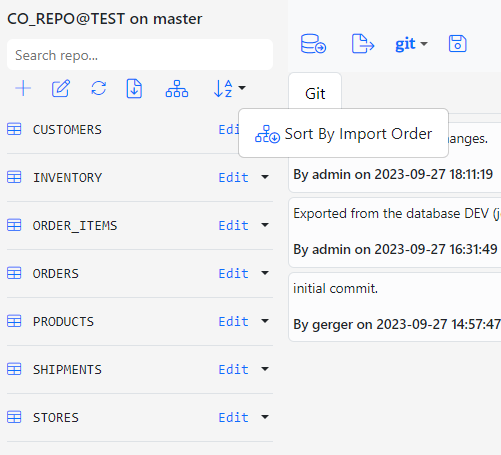
On the main screen, click the first icon on the right in the repo toolbar. Click the Sort By Import Order button to view the entities according to the order they will be imported to the database.
Finally, commit the changes to the import order to the repo.
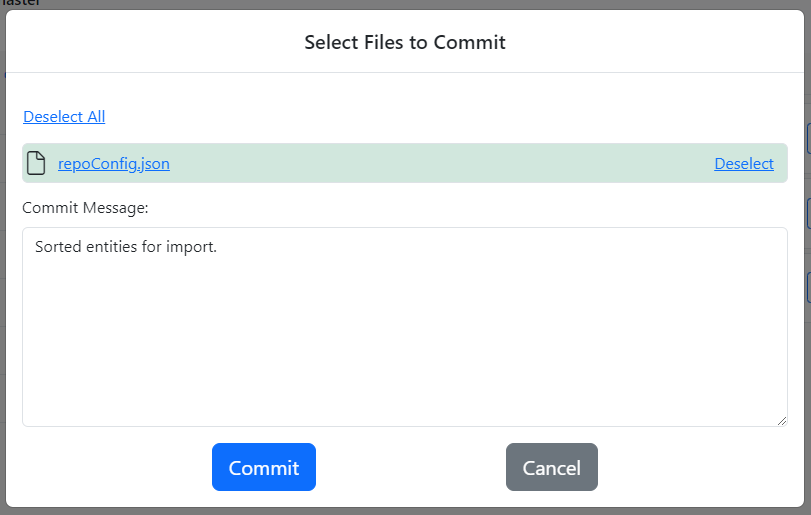
A Note About the repoConfig.json File
repoConfig.json file is the JSON document that stores the Gitora specific information about your repo. It is part of your repo just like any other file. You should commit it to your repo just like any other file.
Moving Changes to Another Database
In the tutorial Getting Started with Gitora For Data , we clones the repo CO_REPO from the DEV database to the TEST database. The repo was empty then. Now we have data in the repo and even some changes.
Go back to the Home screen and open the CO_REPO in the TEST database. A new browser tabs opens displaying the CO_REPO@TEST repo.
From the top menu select git – > Other Gitora Repos – > Pull
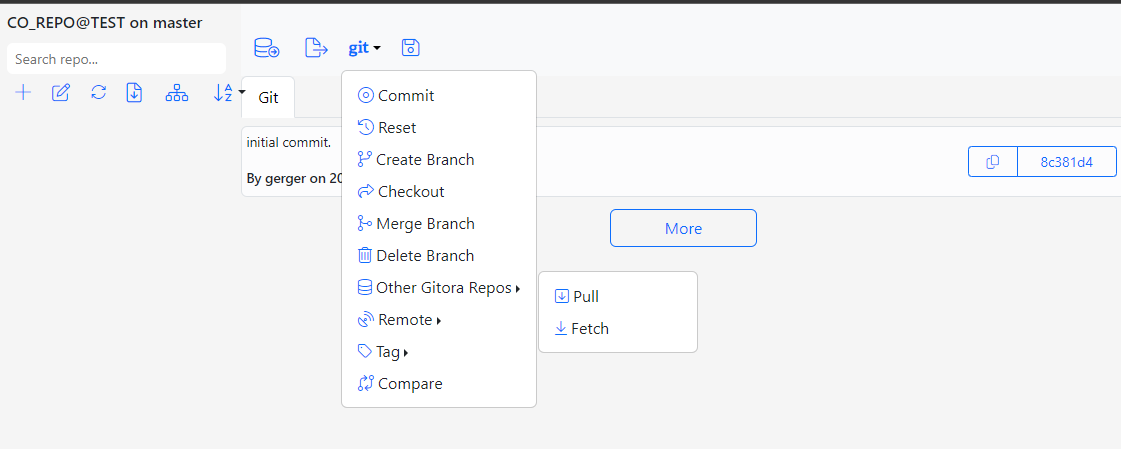
The Pull Dialog shows up. Select the DEV database, the CO_REPO and the master branch from the select boxes respectively.
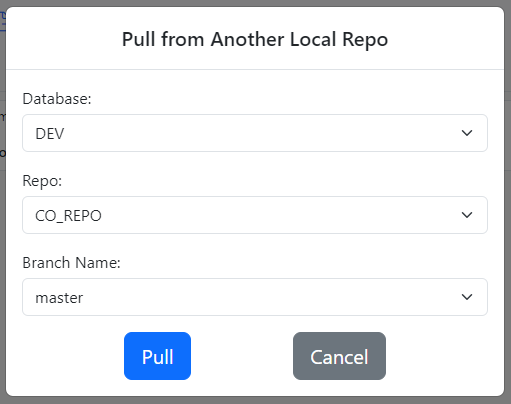
Click the Pull button to move the changes from the CO_REPO@DEV to the CO_REPO@TEST.
The dialog closes and the Repo app is refreshed with the newly pulled commits and entities.
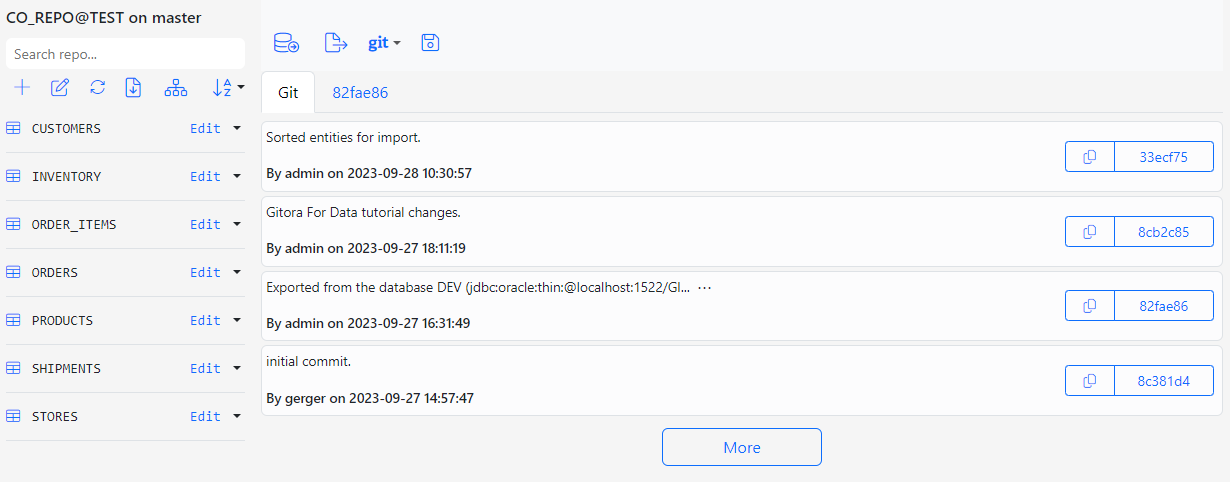
Importing the Data
Gitora For Data generates insert statements based on the data data in the working directory of the git repo. In other words, you should set the state of the files to the commit id you want to import into the database. In this tutorial, we will import the latest version of the data which is already active in the working directory.
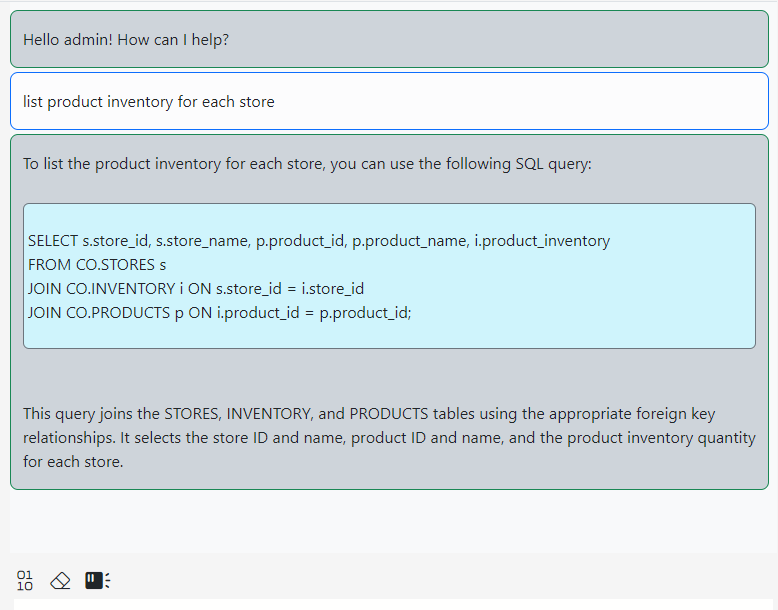
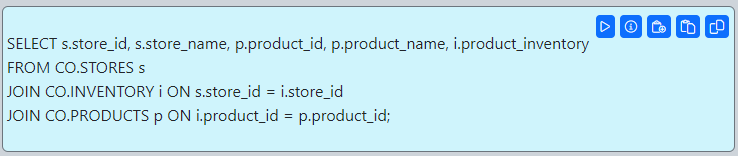
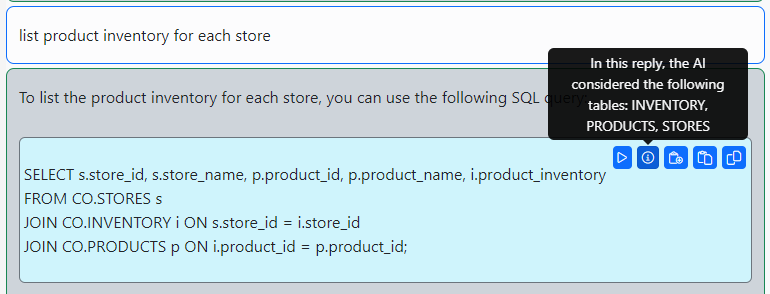
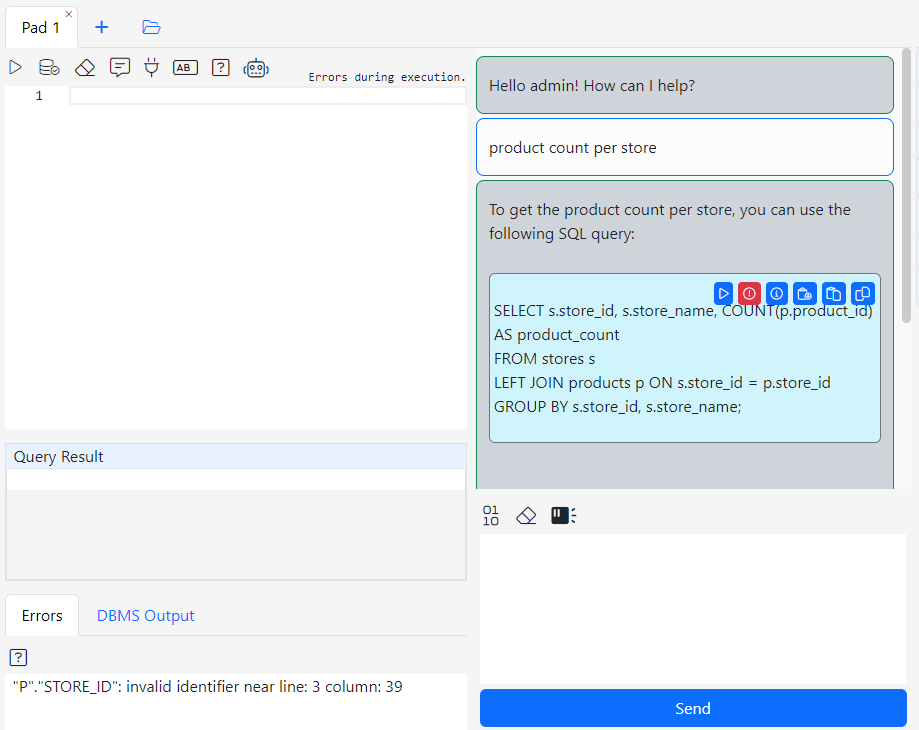
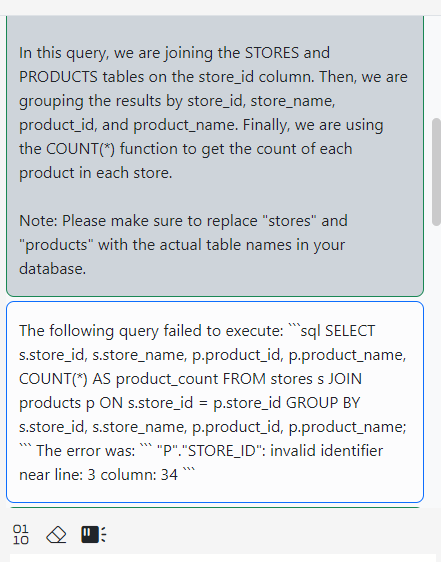
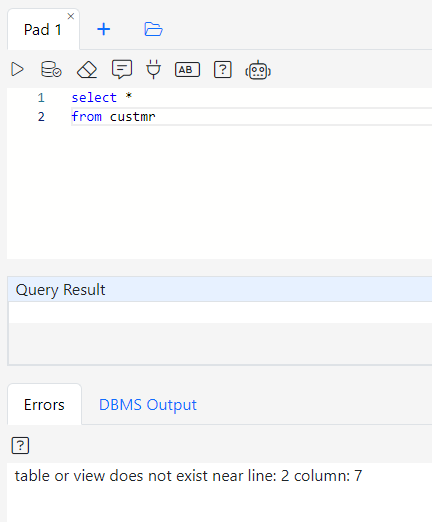
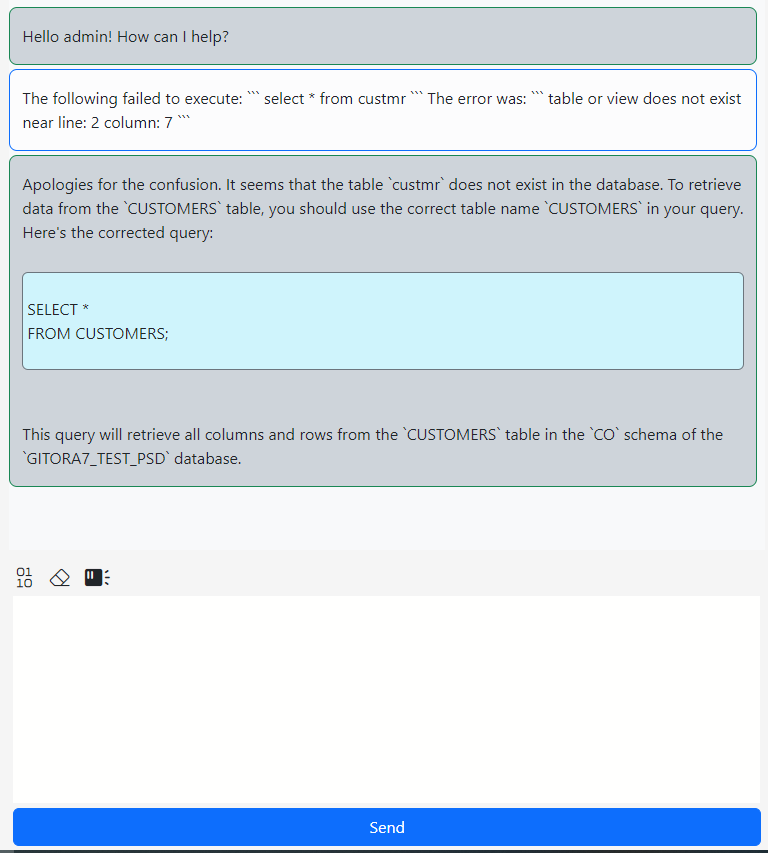
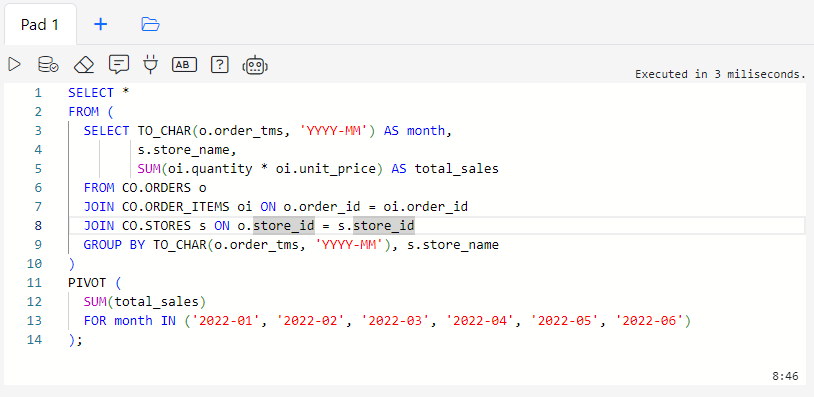
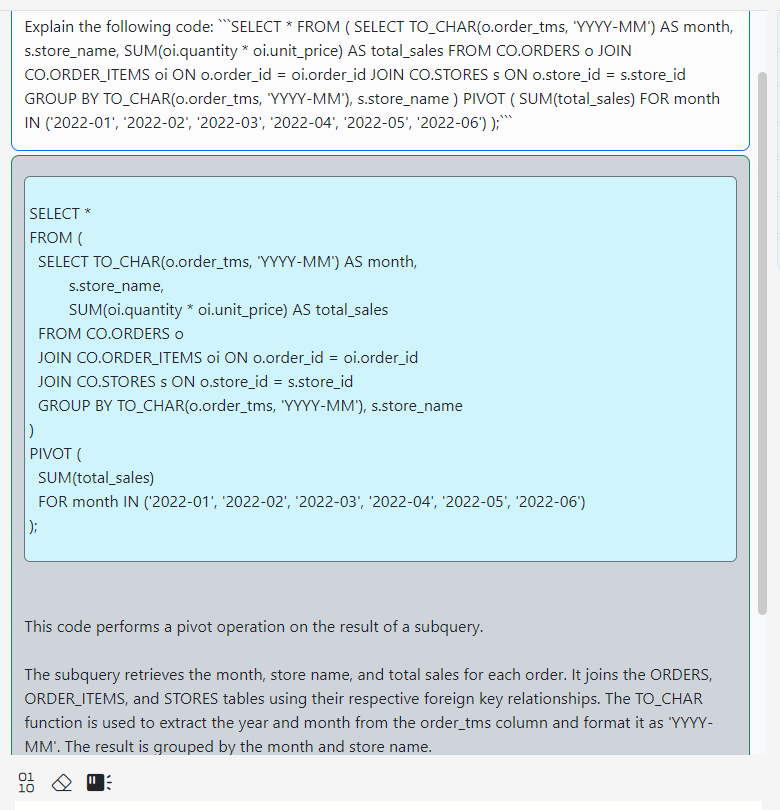
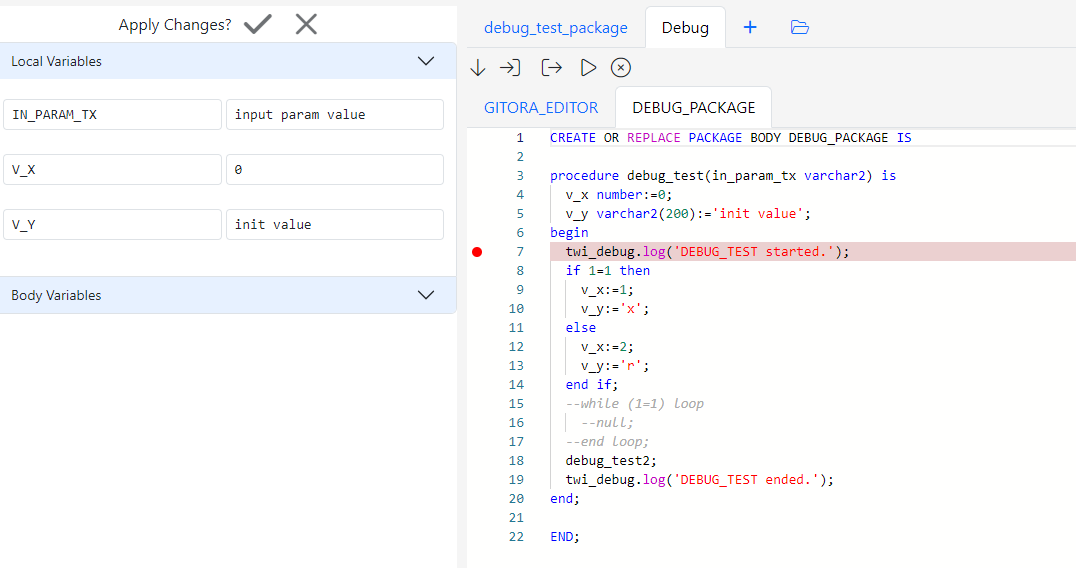
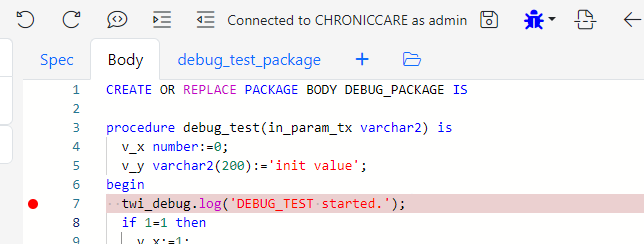
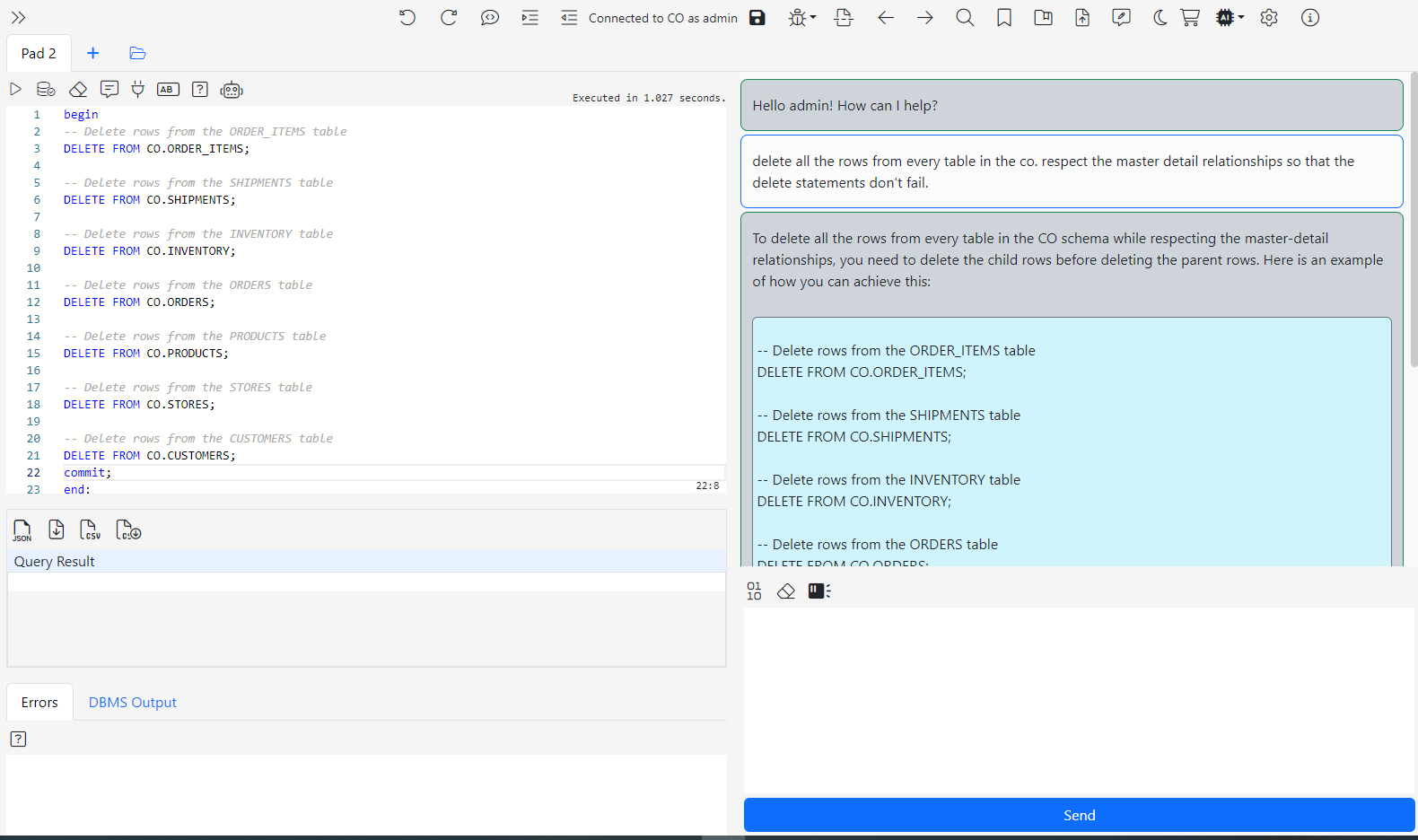
Connect to the CO@TEST database using Gitora PL/SQL Editor. Delete any unwanted rows from the CO schema tables. Since our repo contains all the data we need, we deleted all the rows from the schema by shamelessly plugging our Gitora Editor’s AI Chat feature to this tutorial:
Next, go back to the Gitora For Data app and click the Import button, the second icon from the left.
The Import Dialog shows up.
Click the Import button. Gitora will populate the CO schema with the data in the repo and inform you with a notification and a message in the Messages section at the bottom.
In this tutorial we showed how you can use Gitora For Data to:
- Export data from a database to a Git repo
- Browse and edit the data in the repo and commit the changes.
- Move the repo and import the data to another database.